
- 분류 전체보기 (200)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Binary Search
- Polymolphism
- 자바
- X.org
- Inheritance
- External Scheme
- Entity
- Reference Type
- dbms
- X윈도우
- selenium
- spring
- Operator
- Java
- descriptive statistics
- Class
- OOP
- preprocessing
- python
- 리눅스 마스터 1급
- 백준
- 리눅스
- Unity
- BFS
- Entity Set
- systemd
- Mac
- 셀레니움
- literal
- Physical Scheme
- Today
- Total
Byeol Lo
밑바닥부터 시작하는 딥러닝2 - 1. 신경망 복습 본문
이때 동안 했던 것들을 파이썬을 통해 복습한다.
벡터와 행렬
기본적으로 numpy를 통해 연산을 수행할 수 있다.
import numpy as np
x = np.array([1,2,3])
print(x.__class__) # 클래스명 출력
print(x.shape) # x의 형상, shape 출력
print(x.ndim) # 차원의 깊이 출력
W = np.array([[1,2,3], [4,5,6]])
print(W.shape)
print(W.ndim)보통 x와 같이 하나의 row, column등으로 이루어진 것은 수학이나, 딥러닝의 많은 분야에서 "열벡터" 방식을 선호한다. 하지만 프로그래밍에 있어서 해당 방식은 불편하기 때문에 편의를 고려해 행벡터로 다룬다고 한다(브로드 캐스팅).
행렬의 Eliment-wised Operation
import numpy as np
W = np.array([[1,2,3], [4,5,6]])
X = np.array([[0,1,2], [3,4,5]])
print(W + X)
print(W * X)eliment-wise의 뜻은 원소별로 라는 뜻이고 여기서는 대응되는 원소끼리의 연산으로 생각하면 되겠다.
브로드캐스트
import numpy as np
A = np.array([[1, 2], [3, 4]])
b = np.array([10, 20])
print(A + b)
print(A * b)어떤 numpy객체 간의 연산은 특정 조건을 만족시키면 "브로드캐스팅"이 일어나는데, 원소의 형상(shape)가 맞지 않더라도 shape가 다른 피연산자의 shape에 맞출 수 있다면 연산을 수행할 수 있게 된다.
브로드 캐스팅(Broadcasting)
- 배열의 ndim(차원의 수)이 다른 배열보다 작은 경우, 해당 배열의 모양(shape) 앞에 '1'을 추가한다.
- 출력 모양의 각 차원 크기는 해당 차원의 입력 크기 중 최대값으로 설정된다.
- 입력 배열의 크기가 특정 차원에서 출력 크기와 일치하거나 그 값이 정확히 1이면 해당 입력을 계산에 사용할 수 있다.
- 입력이 특정 차원에서 크기가 1인 경우, 해당 차원의 첫 번째 데이터 항목이 해당 차원의 모든 계산에 사용된다.
브로드캐스팅이 가능한 경우(Broadcastable)
- 두 배열의 모양이 정확히 같은 경우.
- 두 배열의 차원 수가 같고, 각 차원의 길이가 공통 길이 또는 1인 경우.
- 차원 수가 적은 배열은 길이가 1인 차원을 추가하여 위의 속성이 만족되도록 할 수 있다.
벡터의 내적과 행렬의 곱
import numpy as np
x = np.array([1, 2, 3])
y = np.array([4, 5, 6])
print(np.dot(x, y)) # 벡터의 내적
X = np.array([[1, 2], [3, 4]])
Y = np.array([[5, 6], [7, 8]])
print(np.matmul(X, Y)) # 행렬 곱numpy의 두 메서드를 통해 빠른 연산을 수행할 수 있다. 이러한 연산들을 익히기 위해 다음 100 numpy exercises에서 연습을 하자.
https://github.com/rougier/numpy-100
GitHub - rougier/numpy-100: 100 numpy exercises (with solutions)
100 numpy exercises (with solutions). Contribute to rougier/numpy-100 development by creating an account on GitHub.
github.com
행렬 형상(shape) 확인
행렬곱은 연산할 때의 열과 연산하고자 하는 행의 수가 일치해야 하므로 numpy 객체의 shape를 고려하는 것은 필수이다.
import numpy as np
x = np.array([1, 2, 3])
A = np.array([[4, 5, 6], [7, 8, 9]])
print(x.shape)
print(A.shape)
신경망 추론
추론을 inference한다고 얘기하며, 데이터가 한 방향으로 흘러가서 결과를 도출하는 것을 의미한다. 처음 입력되는 부분을 입력층(input layer), 마지막 결과가 나오는 부분을 출력층(output layer), 그 사이의 층들을 은닉층(hidden layer)이라고 부른다.

노란부분이 입력층이며, 입력값은 2개이다. 각 화살표마다 가중치(weight)가 곱해지고 편향(bias)가 더해져 다음 노드 혹은 뉴런으로 전달된다. 이때 뉴런이 활성화가 어느 정도 되냐 안되냐의 여부를 결정짓기 위해 활성화함수(activation function)의 함수를 거치게 된다. 해당 신경망은 Shallow Neural Network 이라고 부르며, 하나의 hidden layer만 가지고 있는 상태를 나타내는 말이다. 여기서 모든 뉴런들이 연결되어 있으므로 해당 신경망을 완전 연결 계층(fully connected layer)이라고 부른다.

Layer들 간의 계산을 표현한 식은 다음과 같다. x가 input이며, 위의 신경망에 적용시 이는 N*2의 형상이 되겠다. N은 미니배치(mini batch)의 크기이며, 데이터들을 하나하나 계산하는 시간을 한꺼번에 계산하여 더 줄일 수 있다. 이렇게 h를 계산했다면, N*3의 행렬이 나오고, Activation function을 거치게 되는데 보통 활성화 함수로는 ReLU를 많이 사용하지만, 여기서는 Sigmoid 함수를 사용하게 된다. 그리고 최근에는 Swish function이라는 함수를 activation function으로 사용했을때, 더 최적화가 잘되는 것을 찾았으며, 해당 식의 계산을 더 간단히 하기 위해 HardSwish function을 더 사용하는 것이 더 좋다고 한다.

Sigmoid를 구현하면 다음과 같다.
def sigmoid(x):
return 1 / (1 + np.exp(-x))
계층으로 클래스화 및 순전파 구현
이제 신경망에서 하는 처리를 계층으로 구현한다. Affine Layer는 완전 연결계층에 의한 변환, Sigmoid 계층은 Sigmoid 함수에 의한 변환으로 구현할 수 있다(다양한 Layer들이 있다). 이러한 계층들은 각각 공통된 특성이 있다.
- 모든 계층은 forward()와 backward() 메서드를 가진다.
- 모든 계층은 인스턴스 변수인 params와 grads를 가진다.
첫번째 특징에 의해 우리는 foward propagation과 backward propagation을 각각의 레이어에 대해 수행 가능하며, params를 통해 가중치와 편향을 확인할 수 있고, grads를 통해 params에 저장된 매개 변수들의 기울기를 저장할 수 있는 리스트이다(가중치 업데이트를 위함). 이제 이를 통해 Sigmoid 계층과 Affine 계층을 구현해보자.

이를 통해 TwoLayerNet이라는 custom layer을 만들어 보자.

신경망의 학습
신경망의 params를 업데이트 하기 위해서 Loss function을 계산해야한다. Multi-classification 문제에서는 cross entropy error을 계산하며, regression 문제에서는 보통 L2 norm을 사용해 계산된다.
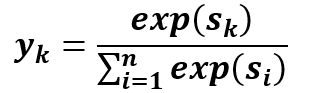

따라서 출력층으로 Softmax를 쓰며, 해당 신경망의 Loss function으로 cross-entropy error를 사용하게 된다. 여기서 t_k는 정답레이블에 1이 들어가는 원-핫 인코딩 된 벡터 형태이다. 따라서 정답이 아닌 원소는 0으로 된다. log는 자연로그이며 밑이 e인 연산이다. 이때 위의 식은 데이터 하나에 대한, 즉 배치처리를 하지 않았을 때의 식이다. 만약 크기가 N인 배치처리를 한다면 다음과 같이 식을 수정할 수 있다.

이렇게 N개의 데이터에 대한 평균을 냄으로 Loss function의 결과로 스칼라 값을 받을 수 있다.
계산 그래프
가중치 업데이트는 모델의 최적화에 있어서 굉장히 중요하다. back propagation으로 loss function에 대한 기울기를 통해 가중치를 업데이트 하는 것은 1권에서도 다뤘었다. 여기서는 계산 그래프에 조금 더 나아가 추가적인 개념들을 더 설명한다.

위는 분기 노드인데, 같은 값이 복제되어 노드로 propagation이 진행되는 형태이다. 위는 back propagation을 진행할 때, 분기한 만큼으로 곱해져서 가중치 업데이트가 진행된다. 이걸 일반화한 것이 Repeat 노드이다.

위와 같이 Repeat 노드는 길이가 D인 배열을 N개로 복제하는 예이다.

위는 Sum 노드의 backward propagation이다. 여기서 Repeat 노드와 Sum 노드는 서로 반대 관계이다. Repeat의 역전파는 Sum 노드의 순전파이며, Sum 노드의 역전파는 Repeat노드의 순전파가 된다.
MatMul 노드
MatMul 노드는 행렬의 곱셈 연산을 수행하는 노드이며, 이 노드의 역전파는 살짝 복잡하다.
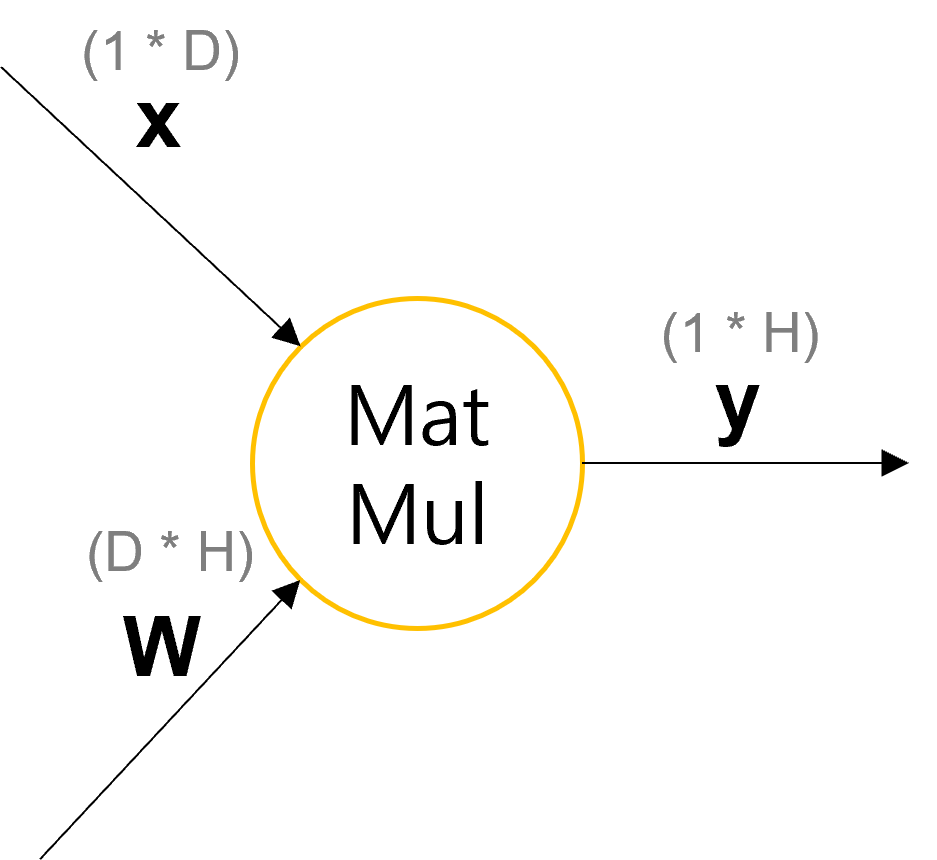
x_1에 대한 Loss function의 편미분을 구해보자면, y의 원소들(y_1, y_2, ..., y_H)를 계산할 때의 모든 연산에 x_1이 사용되므로 모든 y에 대한 편미분 Loss function을 다 합친 것과 같다(Repeat 노드의 back propagation). 따라서 y에 대한 총합이므로 Sigma dL/dy * dy/dx_1가 되게 된다. 이때 나머지 x_2, x_3 또한 같으므로 다음과 같이 일반화할 수 있다.

이때 후자의 편미분 dy_j/dx_i는 W_ij 이므로 위의 식은 결과적으로는 벡터 dL/dx = dL/dy * W^T와 같게 된다.

이때 x가 벡터가 아닌 메트릭스, 미니 배치 형태로 들어오더라도 이제 계산이 원활하게 가능하다.

dL/dX = dL/dY * W^T 이며, dL/dW = X^T * dL/dY 이다. 가장 쉬운 방법은 형상(shape)를 통해서 이해하면 되며, 만약에 직관적으로 안와닿는다면, 데이터 1*D행에 대한 가중치를 업데이트 해야하므로 그에 맞는 가중치를 해당하는, 맞는 노드에 주기 위한 연산이 Transpose 임을 기억하면 된다. 실제로 원소 하나하나 계산을 해보면 해당 위치에 딱 들어맞게 된다. 이를 구현시키면 다음과 같다.
import numpy as np
class MatMul:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.x = None
def forward(self, x):
W, = self.params
out = np.matmul(x, W)
self.x = x
return out
def backward(self, dout):
W, = self.params # 튜플 언패킹
dx = np.matmul(dout, W.T)
dW = np.matmul(self.x.T, dout)
self.grads[0][...] = dW # ellipsis, 주로 다차원 배열을 인덱싱할 때 사용되며, :, :, :, ... 와 같은 의미이다.
return dx위처럼 ellipsis를 쓰는 이유는 shallow copy를 하지 않기 위해서이며, 위와 같이 ellipsis를 쓰면 deep copy를 할 수 있다. 그냥 [0] = dW를 수행하면 주소값을 가져오기 때문에 독립적인 값이 될 수 없다.
class Sigmoid:
def __init__(self):
self.params, self.grads = [], []
self.out = None
def forward(self, x):
out = 1 / (1 + np.exp(-x))
self.out = out
return out
def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dxSigmoid 계층은 1/(1+exp(-x))의 연산을 수행하는 노드이다.
class Affine:
def __init__(self, W, b):
self.params = [W, b]
self.grads = [np.zeros_like(W), np.zeros_like(b)]
self.x = None
def forward(self, x):
W, b = self.params
out = np.matmul(W, x) + b
self.x = x
return out
def backward(self, dout):
W, b = self.params
dx = np.matmul(dout, W.T)
dW = np.matmul(self.x.t, dout)
# repeat 노드의 역전파는 sum 노드의 순전파
# 이때, 형상을 잘보고 어느 축을 기준으로 합을
# 할 것인지 잘 선택해야 함.
db = np.sum(dout, axis=0)
self.grads[0][...] = dW
self.grads[1][...] = db
return dxclass SoftmaxWithLoss:
def __init__(self):
self.loss = None
self.y = None
self.t = None
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return 1 / (1 + np.exp(-x))
def backward(self, dout = 1):
batch_size = self.t.shape[0]
if self.t.size == self.y.size:
dx = (self.y - self.t) / batch_size
else:
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx = dx / batch_size
return dx위의 Layer들은 1권에서 다뤘었으므로 해당 함수들을 가져와 구현한다.
스파이럴 데이터셋
스파이럴(나선형태)의 데이터들을 학습하는 방법을 구현해보자.

# coding: utf-8
import sys
sys.path.append('..') # 부모 디렉터리의 파일을 가져올 수 있도록 설정
import numpy as np
from common.layers import Affine, Sigmoid, SoftmaxWithLoss
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size):
I, H, O = input_size, hidden_size, output_size
# 가중치와 편향 초기화
W1 = 0.01 * np.random.randn(I, H)
b1 = np.zeros(H)
W2 = 0.01 * np.random.randn(H, O)
b2 = np.zeros(O)
# 계층 생성
self.layers = [
Affine(W1, b1),
Sigmoid(),
Affine(W2, b2)
]
self.loss_layer = SoftmaxWithLoss()
# 모든 가중치와 기울기를 리스트에 모은다.
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, x):
for layer in self.layers:
x = layer.forward(x)
return x
def forward(self, x, t):
score = self.predict(x)
loss = self.loss_layer.forward(score, t)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout사용된 모델은 위와 같으며, Affine - Sigmoid - Affine - Softmax 의 신경망이다. 각각은 forward, backward를 통해 순전파 역전파를 쉽게 수행할 수 있고, optimizer(SGD)를 통해 가중치 갱신을 하도록 한다.
import sys
sys.path.append('..') # 부모 디렉터리의 파일을 가져올 수 있도록 설정
import numpy as np
from common.optimizer import SGD
from dataset import spiral
import matplotlib.pyplot as plt
from two_layer_net import TwoLayerNet
# 하이퍼파라미터 설정
max_epoch = 300
batch_size = 30
hidden_size = 10
learning_rate = 1.0
# 데이터 읽기, 모델과 옵티마이저 생성
x, t = spiral.load_data()
model = TwoLayerNet(input_size=2, hidden_size=hidden_size, output_size=3)
optimizer = SGD(lr=learning_rate)
# 학습에 사용하는 변수
data_size = len(x)
max_iters = data_size // batch_size
total_loss = 0
loss_count = 0
loss_list = []
학습을 위한 모든 객체를 가져왔고 변수들을 선언했다. 이제 실제 학습 과정들을 구현하자.
for epoch in range(max_epoch):
# 데이터 뒤섞기
idx = np.random.permutation(data_size)
x = x[idx]
t = t[idx]
for iters in range(max_iters):
batch_x = x[iters*batch_size:(iters+1)*batch_size]
batch_t = t[iters*batch_size:(iters+1)*batch_size]
# 기울기를 구해 매개변수 갱신
loss = model.forward(batch_x, batch_t)
model.backward()
optimizer.update(model.params, model.grads)
total_loss += loss
loss_count += 1
# 정기적으로 학습 경과 출력
if (iters+1) % 10 == 0:
avg_loss = total_loss / loss_count
print('| 에폭 %d | 반복 %d / %d | 손실 %.2f'
% (epoch + 1, iters + 1, max_iters, avg_loss))
loss_list.append(avg_loss)
total_loss, loss_count = 0, 0train_custom_loop.py에 들어있는 소스코드들을 통해 하나하나 살펴볼 수 있다. permutation을 통해 사이즈만큼의 0~ data_size-1까지의 원소가 들어있는 리스트를 랜덤으로 섞을 수 있으며, indexing을 통해 섞은 순서대로 저장한다. 그 이후에는 batch size만큼의 학습을 수행하는데, forward를 통해 마지막의 softmax with loss layer에서 반환된 loss를 받고, model의 backward를 통해서 층의 각각의 갱신되는데 필요한 편미분 값들을 계산하며, optimizer를 통해 갱신되는 방식을 정하고, learning late를 통해 업데이트 한다. 여기까지가 핵심이다.
계산 고속화
신경망의 학습에서 사용될 연산량은 상당해서 얼마나 빠르게 연산을 수행하냐가 관건이다. 따라서 '비트 정밀도'와 'GPU'라는 개념이 나오게 된다.
import numpy as np
a = np.random.randn(3)
print(a.dtype)넘파이는 기본적으로 64비트 데이터 타입을 사용하는데, 실제로 64비트 부동소수점 수가 사용되는지 위의 코드를 통해 알 수 있다. 신경망의 추론과 학습은 64비트가 아니라 32비트로 수행해도 충분히 문제가 없이(인식률을 거의 떨어뜨리는 일 없이) 수행가능하다고 한다. 따라서 컴퓨터 자원의 측면에서 32비트 부동소수점 수를 더 선호한다. 또한 학습이 아니라 추론까지 한정하면 16비트도 무리가 없다고 한다. 근데 CPU와 GPU의 연산 자체가 32비트로 수행하기 때문에, 16비트로 변환하여 연산을 하더라도 메리트가 없다. 따라서 학습된 가중치를 파일로 저장할때만 16비트로 저장하되, 학습하거나 추론할 때에는 32비트를 사용한다.
64비트를 32비트 연산으로 바꾸는 것 외에도 GPU를 사용한 병렬 계산을 수행하는 것도 연산을 빠르게 하는 방법이다. 이를 위해 nvidia에서는 cuda라는 컴퓨팅 플랫폼을 제공하는데, 사용법은 numpy와 거의 유사하며, import numpy as np를 import cupy as np로만 바꾸면 된다. cuda를 사용하기 위해서 다음 공식 홈페이지에서 다운받아주도록 하자.
https://developer.nvidia.com/cuda-toolkit
CUDA Toolkit - Free Tools and Training
Get access to SDKs, trainings, and connect with developers.
developer.nvidia.com
이제 매우 깊은 신경망도 연산을 빠르게 수행할 수 있도록 준비를 끝마쳤다. 복잡한 데이터들에 대한 신경망 학습도 할 수 있게 된 것이다.
'AI' 카테고리의 다른 글
| AI 용어들 (0) | 2023.06.23 |
|---|---|
| 밑바닥부터 시작하는 딥러닝1 - 5. 합성곱 신경망 CNN (0) | 2023.06.15 |
| 밑바닥부터 시작하는 딥러닝1 - 4. 학습 기법 (2) | 2023.06.14 |
| 밑바닥부터 시작하는 딥러닝1 - 3. 오차역전파 (0) | 2023.06.14 |
| 밑바닥부터 시작하는 딥러닝1 - 2. 처리과정에서의 용어들 (0) | 2023.06.07 |


