
- 분류 전체보기 (205)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Polymolphism
- descriptive statistics
- OOP
- Entity
- External Scheme
- Java
- Unity
- preprocessing
- Mac
- systemd
- X윈도우
- Physical Scheme
- 셀레니움
- 리눅스
- X.org
- 자바
- Inheritance
- dbms
- 백준
- Reference Type
- Operator
- Entity Set
- python
- BFS
- Class
- 리눅스 마스터 1급
- literal
- selenium
- Binary Search
- spring
- Today
- Total
Byeol Lo
밑바닥부터 시작하는 딥러닝1 - 4. 학습 기법 본문
다음은 머신러닝에서 자주 다룰 개념들이다.
- 최적화(Optimization)
- 하이퍼 파라미터(Hyper Parameter)
- 오버피팅(Overfitting)
위 세 주제에 대해 다뤄지는 기법들을 소개한다.
우선 Optimization는 데이터의 분포에 맞게 신경망을 학습시키는 과정을 말한다. 다음은 신경망의 가중치들을 업데이트하는 수식이다. 최적화를 하는 방법에도 많은 기법들이 소개되는데, 여기서 다뤘던 것은 SGD였다.
확률적 경사하강법(SGD : Stocastic Gradient Descent)

여기서 에타는 학습률(learning rate), 학습률과 곱해진 것은 여태 편미분을 통해 계산했던 역전파 값이다. 이 둘을 통해 가중치를 업데이트 한다. 여기서 Loss Function에 따라 신경망에게 피드백을 해주는 것이고, 미니 배치 처리를 통해 배치에 대한 손실 함수를 계산하게 된다. 이런 과정을 우리는 앞서 확률적 경사하강법 SGD(Stocastic Gradient Descent)라고 불렀다. 하지만 이런 최적화 기법은 단점이 존재한다. 가령 데이터 분포가 다음과 같이 f(x, y) = x^2/200 + y^2 + b (b ~ N(0, ?))를 따른다고 하자. 이때, 분포의 모습은 x축의 방향으로 길게 늘어트린 곡면 형태이다. 여기서 우리가 찾고 싶었던 가장 최적의 파라미터는 (0, 0) 이겠지만,대부분의 지점에서 기울기는 (0, 0)을 가르키고 있지 않다.
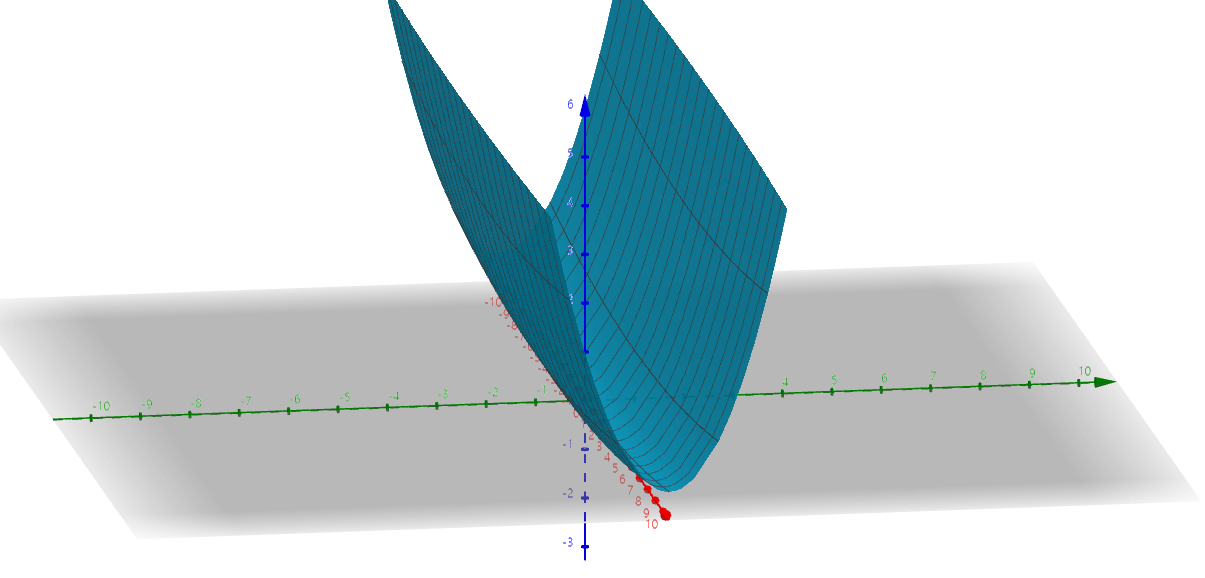
따라서 이럴 때는 학습을 계속하더라도 매우 느린 최적화를 보인다. 이런 SGD의 단점을 보완하기 위해 모멘텀, AdaGrad, Adam이라는 방법들이 나오게 된다.
모멘텀 Momentum

위에서 봤던 수식과 유사하게 가중치를 업데이트하지만 갱신 값의 의미가 다르다. v는 velocity 속도 이며, 이 수식의 의미는 기울기 방향으로 힘을 받아 물체가 가속된다는 물리 법칙을 나타낸다. 알파값은 보통 0.9로 설정하며, 알파 * 속도 항은 물체가 아무런 힘을 받지 않을 때 서서히 하강시키는 역할을 한다.
AdaGrad
신경망 학습에서는 학습률(learning rate)가 중요한데, 이 학습률을 정하는 효과적 기술로 학습률 감소(learning rate decay)가 있다. 이는 학습을 진행하면서 학습률을 점차 줄여가는 방법인데, 처음에는 크게 학습하다가 조금씩 작게 학습한다는 얘기다. 나아가 이를 더 발전시켜 각각의 매개 변수 에 맞게 적절한 학습률 값을 지정해주는 것이 AdaGrad이다.

여기서 특징은 과거의 기울기를 제곱하여 계속 더한 것을 축적하는데, 이를 나눠주어(결국 제곱의 합의 루트) 학습률이 낮아지게 된다.
AdaGrad는 실제로 학습을 진행할수록 갱신 강도가 약해지는데, 어느 순간 갱신량이 0이 되어 갱신이 되지 않게 된다. 이를 해결한 것이 바로 RMSProp라는 방법이며, 과거의 모든 기울기를 균일하게 더해가는 것이 아니라, 먼 과거의 기울기는 서서히 잊고 새로운 기울기 정보를 크게 반영하게 된다. 이런 과거 기울기 반영 규모를 기하급수적으로 감소시키는 것을 지수이동평균(EMA)라고 한다.
Adam
모멘텀은 공이 구르는 움직임을, AdaGrad는 매개변수의 원소마다 적응적으로 갱신 정도를 조정한다. 이 두가지를 합친게 Adam이다. 이는 나중에 논문 리뷰를 통해 살펴보자. 현재로써는 이 방법이 그나마 자주 쓰이는 방법이다.
Adam은 하이퍼 파라미터를 3개 가지고 있으며, 지금까지의 학습률(learning rate), 나머지 두개는 일차 모멘텀용 계수 베타1(=0.9)과 이차 모멘텀용 계수 베타2(=0.999)로 한다.
모델들의 파라미터들을 갱신하는 방법 또한 최적화의 중요한 요소지만, 가중치의 초깃값도 빼놓을 수 없다. 위의 가중치 갱신이 전부 초깃값(출발지점)으로 부터 시작하여 미끄러져 내려가 최종 지점(최적화가 되는 곳, loss function이 local minimum)에서 주행을 멈추게 되는 것으로 해석한다면, 우리는 출발지점을 어떻게 잡느냐에 따라 수많은 local minimum을피하고, global minimum에 가까워질 수 있도록 하는게 목표이다.
그러기 위해서는 가중치의 초기 설정이 굉장히 중요하다. 데이터가 한 레이어, 두 레이어, ... 거칠 때마다 데이터는 변환된다. 각 층의 노드 각각은 전부 초기 데이터와 다른 데이터들을 마주하게 되고, 가중치들은 그 데이터들에 맞는 초기값을 가져야 한다. 따라서 우리 뇌의 가중치들을 흉내낼 수는 없지만, 각 층의 활성화 값은 적당하게 고루 분포되어야 하며, 층과 층 사이에 적당하게 다양한 데이터가 흐르게 해야 신경망 학습이 효율적으로 이뤄지게 된다(반대로 너무 치우친 데이터가 흐르면 기울기 소실이나 표현력 제한 문제에 빠져서 학습이 잘 이루어 지지 않는다고 한다).
Xavier 초깃값
사비에르 글로로트와 요슈아 벤지오의 논문에서 권장하는 가중치 초깃값인 Xavier 초깃값을 써서 일반적인 딥러닝 프레임워크들에게 사용되어진다. 각 층의 앞선 층"들"이 n개의 노드를 가지고 있다면, 이 층의 노드들에 대한 가중치 초깃값들은 표준편차가 1/sqrt(n)이 되도록 설정한 것이다.

위는 그 결과이며, 가중치를 넓게 분포시킬 수 있는 장점이 있다.
층이 깊어질수록 일그러지는데, 이는 활성화 함수로 tanh 함수를 사용하면 개선된다고 한다. (활성화 함수 용으로는 원점에서 대칭인 함수가 바람직하다고 알려져 있다.)
He 초깃값
Xavier 초깃값은 활성화 함수가 선형인 것을 전제로 이끈 결과이다(Sigmoid 함수와 tanh함수는 좌우 대칭이라 중앙 부근이 선형임). 반면 비선형 함수인 ReLU는 카이밍 히가 찾아낸 He 초깃값을 쓴다. 이는 앞 계층의 노드가 n개일 때, 표준편차가 sqrt(2/n)인 정규 분포를 사용한다. ReLU는 음의 영역이 0이기 때문에 2배의 계수가 필요하다고 직관적으로 해석할 수 있다.
Batch Normalization(배치 정규화)
이때까지 앞 절에서는 각 층의 활성화 값 분포들을 설정하여, 각 층의 활성화값 분포가 적당히 퍼지면서 학습이 원할하게 수행됨을 배웠는데, 굳이 이렇게 하지 않고, 층을 하나를 새로 만들어 데이터들을 골고루 퍼뜨려 활성화를 적당히 퍼뜨리도록(활성화가 되는지 안되는지) 강요하게 할 수 있다.

위는 Affine Layer와 Activation Layer 사이에 배치 정규화 계층(Batch Norm Layer)을 끼워 넣어 만든 것이다. 배치 정규화는 그 이름과 같이 학습 시 미니 배치를 단위로 데이터들을 정규화(Normalization)하는 Layer이다. 밑은 그에 대한 수식이다.

통계에서 데이터를 N(0, 1)로 바꾸는 것과 동일하지만 마지막의 엡실론을 넣는다. 이는 10e-7등의 값으로 0으로 나누는 사태를 막기 위함이다. 그리고 저기서 그치지 않고, 정규화 된 데이터에 대해 확대(scale)과 이동(shift) 변환을 수행한다.

위의 감마는 확대scale를, 베타가 이동shift를 담당하게 된다. 보통은 감마=1, 베타=0으로 설정하며 여기까지 과정이 배치 정규화 알고리즘이다. 또한 얘도 back propagation을 할때 역전파 값을 구해줘야 하는데, 이는 나중에 시간되면 다뤄보자.
기계학습에서는 오버피팅 문제가 많이 발생한다. 이는 저번에 봤던 수학 문제 A에 대해서는 정답만을 학습을 하여 잘 풀지만, 그 외의 B에 대해서는 A에 대한 정답만을 학습했기 때문에 잘 풀지 못하는 것이다. 오버피팅은 주로 두 가지 경우에 일어나는데,
- 매개변수가 많고, 표현력이 높은 모델
- 훈련 데이터가 적음
이다. 이는 훈련 데이터(train data)와 시험 데이터(test data)에 대한 정확도를 통해 정말 Overfitting이 일어났는지 확인 할 수 있다.

가중치 감소
오버피팅을 막기 위해 가중치 감소(weight decay)를 쓸 수 있는데, 이는 그냥 손실함수에 학습 과정에서 큰 가중치에 대해서 그에 대응되는 큰 페널티를 부과하는 것이고, 손실함수에 가중치의 L2 노름이나 L1, L_inf 노름을 더하는 것으로 이를 막을 수 있다.

위는 가중치 감소를 적용한 loss function의 예이다.
드롭아웃
가중치 감소는 손실 함수를 조정하여 간단하게 오버피팅을 막을 수 있었다면, 복잡한 신경망에 대해서는 가중치 감소만으로는 대응하기 힘들다. 이를 위해 나온 것이 드롭아웃(Dropout)이라는 기법이다. 이는 뉴런을 임의로 몇개 삭제하여 학습하는 방법인데, 삭제된 뉴런은 신호를 전달하지 않게 된다.

하이퍼 파라미터(각 층의 뉴런 수, 배치 크기, 매개변수 갱신 시의 학습률, 가중치 감소)들을 적절히 설정하지 않으면 모델의 성능이 크게 떨어지기도 한다. 그러면 이런 값을 어떻게 설정하냐, 어떻게 탐색하냐가 문제이다.
검증 데이터
지금까지 데이터셋을 훈련 데이터와 시험 데이터라는 두 가지로 분리해 이용했다. 훈련 데이터로는 학습을 하고 시험 데이터로는 범용 성능을 평가했다. 그러면 하이퍼파라미터를 다양한 값으로 설정하고 검증을 하고 싶은데, 이럴 때는 어떻게 해야하는가가 문제이다. 이때 사용하는 것이 검증 데이터이다. 이때 시험 데이터를 사용하여 하이퍼파라미터를 조정하면 하이퍼파라미터 값이 시험 데이터에 오버피팅되기 때문에 즉, 하이퍼 파라미터 값이 좋음을 시험 데이터로 확인하게 되므로 시험데이터에만 적합하도록 강요된다. 따라서 따로 전용 확인 데이터(valid data)가 필요하다. 정리하면 다음과 같다.
- 훈련 데이터Train data : 매개변수 학습
- 검증 데이터Valid data : 하이퍼파라미터 성능 평가
- 시험 데이터Test data : 신경망의 범용 성능 평가
검증 데이터는 훈련 데이터에서 일정 비율%로 추출하여 검증 데이터를 생성할 수 있다.

- 0단계 : 하이퍼 파라미터 값의 범위를 설정한다.
- 1단계 : 설정된 범위에서 하이퍼파라미터의 값을 무작위로 추출한다.
- 2단계 : 1단계에서 샘플링한 하이퍼파라미터 값을 사용하여 학습하고, 검증 데이터로 정확도를 평가한다(단, 에폭은 작게한다)
- 3단계 : 1단계와 2단계를 특정 횟수(100회 등) 반복하며, 그 정확도의 결과를 보고 하이퍼파라미터의 범위를 좁힌다.
하지만 이는 전혀 과학적이지 않은 방법이지만, 더 세련된 기법이 있다면 베이즈 최적화의 논문을 참고하여 공부하자.
'AI' 카테고리의 다른 글
| AI 용어들 (0) | 2023.06.23 |
|---|---|
| 밑바닥부터 시작하는 딥러닝1 - 5. 합성곱 신경망 CNN (0) | 2023.06.15 |
| 밑바닥부터 시작하는 딥러닝1 - 3. 오차역전파 (0) | 2023.06.14 |
| 밑바닥부터 시작하는 딥러닝1 - 2. 처리과정에서의 용어들 (0) | 2023.06.07 |
| 밑바닥부터 시작하는 딥러닝1 - 1. 퍼셉트론 (0) | 2023.06.07 |


