
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 자바
- 리눅스 기초
- BFS
- dbms
- python
- Inheritance
- zsh
- Operator
- 셀레니움
- X.org
- Class
- Physical Scheme
- 리눅스 마스터 1급
- Polymolphism
- Mac
- External Scheme
- Binary Search
- 백준
- selenium
- Unity
- OOP
- Java
- 리눅스
- Reference Type
- Entity Set
- preprocessing
- Entity
- literal
- X윈도우
- systemd
- Today
- Total
Byeol Lo
[ADP] 2장 데이터 처리 기술의 이해 - 데이터 처리 기술, 분산 데이터 저장 기술 본문
분산 데이터 저장 기술로는 다음으로 나눌 수 있다.
- 분산 파일 시스템
- 클러스터 데이터베이스
- Key-Value 저장소(NoSQL)
분산 파일 시스템
클라이언트/서버 모델의 분산 파일 시스템으로는 시스템 성능과 확장에 한계가 있기에 요새는 Asymmetric 클러스터 파일시스템을 통해 파일 메타데이터를 관리하는 전용 서버를 별도로 둬서 메타데이터에 접근하는 경로와 데이터에 접근하는 경로를 분리해, 이를 통해 파일 입출력 성능을 높이면서 독립적인 확장과 안전한 파일 서비스를 제공함. 분산 파일 시스템의 종류로는 다음이 있다.
- GFS(Google File System)
- HDFS(Hadoop Distributed File System)
- 러스터
GFS
- Fault Tolerance:
- Chunk Server에서의 Fault Tolerance: master node 에서 주기적으로 하트비트(Heartbeat) 메시지를 이용하여 chunk 서버에 저장된 chunk의 상태를 체크하여 상태에 따라 chunk를 재복제하거나 재분산하는 것과 같은 회복동작을 수행.
- Master Server에서의 Fault Tolerance: master node에 대한 장애 처리와 회복을 위해 파일시스템 name space와 파일의 chunk 매핑 변경 연산을 로깅하고 마스터의 상태를 여러 shadow master에 복제함(push).
- Large Files: 대부분의 파일은 대용량임
- Optimize for Reads + Appends: 시스템은 읽기 또는 추가 작업에 최적화 되어 있음, atomic한 연산을 지원하며 write-once-read-many model을 따름, master는 하나의 chunk 서버를 primary로 지정하여 복제본의 갱신 연산을 일관되게 처리할 수 있도록 보장함.
- High and Consistent Bandwidth: 전체 데이터 양의 흐름은 일관되어야 함. chunk가 기본 데이터 흐름 단위이며, 기본적으로 64MB이다.
GFS Read Operation

- Client가 읽고 싶은 데이터에 대한 Meta data(chunk handle와 chunk locations)를 GFS master에게서 받게 된다.
- 받은 Meta data를 통해 chunk 서버로 파일 데이터를 요청한다.
- 해시테이블(리눅스 파일 시스템을 따름)을 활용해 데이터를 chunkserver 에서 읽어들이고,
- GFS server는 받은 입출력 요청을 처리하고 chunk data를 반환시킨다.
HDFS
GFS의 아키텍처 및 사상을 그대로 구현한 Cloning project이다.

전체적인 구조는 위와 같은데 하나의 네임노드(name node)와 다수의 데이터노드(data node)로 구성되고, 네임노드는 파일 시스템의 이름 공간을 관리하면서 클라이언트로부터 파일 접근 요청을 처리한다. HDFS에서 파일 데이터는 블록 단위로 나뉘어 여러 데이터 노드에 분산/저장되며, 블록들은 가용성을 보장하기 위해 다시 복제/저장된다(GFS의 3개 복제하는거랑 같음).
- Data Node: 클라이언트로부터의 데이터 I/O 요청을 처리하며, HDFS에서 Write-Once-Read-Many 모델을 따른다.
- Name Node: 데이터 노드들로부터 하트비트(Heartbeat)를 주기적으로 받으면서 데이터 노드들의 상태를 체크함. 하트비트 메시지에는 블록 정보를 가지고 블록의 상태를 체크할 수 있다.
- HDFS: 클라이언트, 네임노드, 데이터노드 간의 통신을 위해 TCP/IP 네트워크 상에서 RPC(Remote Procedure Call)을 사용
Lustre
러스터는 클러스터 파일 시스템에서 개발한 객체 기반 클러스터 파일 시스템이며, 구성요소는 다음과 같다.
- MDS(Metadata Server): 파일 시스템의 메타데이터(파일 이름, 디렉토리 구조, 접근 권한 등)을 관리, 클라이언트의 요청을 처리하여 메타데이터의 R/W를 담당
- MDT(Metadata Target): MDS에서 관리하는 메타데이터를 실제로 저장하는 저장소
- OSS(Object Storage Server): 파일의 실제 데이터 블록을 분산 저장하고, 클라이언트의 객체 데이터 입출력 요청을 처리한다. 여기서 객체들은 객체 저장 서버들에 스트라이핑(striping, 연속된 데이터를 여러 개의 디스크에 라운드 로빈 방식으로 기록하는 기술. 여러 개의 디스크를 더 빠르게 읽을 수 있을 때 유용함. 즉, 병렬처리에 유리하다는 것)되어서 저장된다.
이 요소들이 전부 고속 네트워크(TCP/IP, Infiniband, Myrinet)으로 연결되어서 통신을 한다.

- 라이트백 캐시(Write Back Cache): 파일 메타데이터에 대해서는 지원하는 기술인데, 클라이언트 측에서 메타데이터 변경에 대한 갱신 레코드를 생성하고 이를 임시로 캐싱한 뒤 나중에 한꺼번에 MDS로 전달하는 기술이다.
- UNIX 시멘틱 지원, 파일 수정 지원, chunk based 가 아님(위 두 file system과 다른 점)
- 메타데이터에 접근하기 위해 메타데이터 서버의 잠금 요청으로 접근 의도를 같이 전달하는 인텐트(intent) 기반 lock 프로토콜 사용
- 메타데이터 서버 간의 네트워크 트래픽을 줄임
밑을 보기전에 보고 가자.
클러스터: 여러 노드가 하나의 시스템처럼 동작하도록 구성된 집합체이며, 여러 컴퓨터 또는 서버 컴퓨터가 하나의 시스템처럼 동작하도록 구성된 집합체임. 주로 고가용성, 부하 분산, 성능 향상을 목적으로 구성됨
인스턴스: 실행 중인 특정 소프트웨어의 한 복사본, 데이터베이 인스턴스라면 데이터베이스 관리 시스템이 메모리와 프로세스에서 실행되는 것임. 노드가 여러개 실행되면 메모리에 여러개 올라와 있다는 뜻.
데이터베이스 클러스터
- Oracle RAC 데이터베이스 서버
- IBM DB2 ICE
- Microsoft SQL Server
- MySQL
파티셔닝: 데이터를 효율적으로 관리하기 위한 데이터 나누는 방법
클러스터링: 데이터를 나누긴 하지만 클러스터 별로 데이터의 특성이 동일하도록 만듦
여기서 파티셔닝을 보자.
- 파티션 사이의 병렬 처리를 통한 빠른 데이터 검색 및 처리 성능을 얻을 수 있음
- 성능의 선형적인 증가 효과를 볼 수 있음
- 특정 파티션에서 장애가 발생하더라도 서비스가 중단되지 않는 고가용성을 확보할 수 있음
파티셔닝은 종류가 보는 관점에 따라 다른데,
- DBMS를 구축하는 형태에 따라 단일 서버 내의 파티셔닝과 다중 서버 사이의 파티셔닝으로 구분할 수 있다.
- 단일 서버 파티셔닝: 하나의 물리적 서버 내에서 데이터를 여러 파티션으로 나누어서 저장하는 방식
- 다중 서버 파티셔닝: 여러 물리적 서버에 데이터를 분산시켜서 저장하는 방식
- 리소스 공유 관점에서는 공유 디스크(Shared Disk)와 무공유(Shared Nothing)로 다시 나뉜다.
- Shared Disk
- "논리적"으로 모든 데이터베이스 인스턴스 노드들과 공유
- 각 인스턴스는 모든 데이터에 접근할 수 있음(독립적으로 접근하는 것처럼 보임)
- 데이터를 공유하려면 SAN(Storage Area Network)과 같은 공유 디스크가 필요
- 모든 노드가 수정할 수 있기 때문에 노드 간의 동기화 작업 수행을 위한 별도의 커뮤니케이션 채널이 필요
- 장점은 높은 수준의 fault-tolerance를 제공함: 클러스터를 구성하는 노드 중 하나의 노드만 살아 있어도 서비스가 가능
- 단점은 커지면 디스크 영역에서 병목 현상이 발생
- Shared Nothing
- 클러스터는 자신이 관리하는 데이터 파일을 자신의 로컬 디스크에(물리적으로) 저장하며
- 노드 간에 공유 없음
- 각 클러스터는 완전히 분리된 데이터의 서브 집합에 대한 소유권을 가짐, 그래서 각 인스턴스가 데이터에 대한 요청을 처리
- 장점은 확장에 제한이 없음
- 단점은 각 노드에 장애가 발생할 경우를 대비하여 각 노드에 별도의 fault-tolerance를 구성해야 함, 까다로움
- Shared Disk
Oracle RAC
기본적으로 Shared Disk 방식이며, 일반적인 4노드 RAC 구성 모델이다. Oracle RAC DB Server 는 클러스터의 모든 노드에서 실행되며, 데이터 공유 스토리지에 저장된다. 클러스터의 모든 노드는 데이터베이스의 모든 테이블에 동등하게 액세스 할 수 있고, 특정 노드가 데이터를 소유한다는 개념이 없다. 따라서 데이터를 파티셔닝할 필요가 없지만, 성능 향상을 위해 빈번하게 파티셔닝 된다. 응용 프로그램은 클러스터의 특정 노드가 아니라 RAC 클러스터에 연결하며, RAC는 클러스터의 모든 노드에 로드를 고르게 분산한다.

- 가용성: 높은 수준의 Fault-tolerance가 제공
- 확장성: 추가 처리 성능이 필요하면 응용 프로그램이나 DB를 수정할 필요 없이 새 노드를 클러스터에 쉽게 추가할 수 있음
- 비용 절감: 표준화된 소규모(CPU 4개 미만) 저가형 상용 하드웨어의 클러스터에서도 고가의 SMP 시스템 만큼 효율적으로 응용 프로그램을 실행함으로써 하드웨어 비용을 절감할 수 있음. 4CPU(쿼드 코어여야 할 듯)의 16노드 클러스터를 사용하면 동급 성능의 64CPU SMP 시스템에 비해 비용을 크게 절감할 수 있음

위는 oracle RAC의 구성도이다. 현재 2 개의 RAC 인스턴스를 사용하고 있고, 각 RAC 인스턴스는 Oracle Automatic Storage Management(ASM)을 사용하여 데이터를 관리한다. 또한 지금 virtual box 안에서 가상 환경에 설정된 구성이다. RACVM을 통해서 RAC를 가상화 환경에서 실행하여 공유 스토리지를 관리할 수 있게 된다. 각 가상머신에는 고유의 IP 주소가 할당되고, 공용 네트워크와 사설 네트워크로 분리된다. 두 RAC 노드는 비밀번호가 없는 SSH를 통해서 (Secure Shell 접속 시 비밀번호를 입력하지 않고 자동으로 인증을 수행하는 방법) 고가용성을 달성하고 있다.
IBM DB2 ICE(Integrated Cluster Environment)
DB2는 CPU/메모리/디스크를 파티션 별로 독립적으로 운영하는 Shared Nothing 방식의 클러스터링을 지원하며, 어플리케이션은 여러 파티션에 분산된 데이터베이스를 하나의 데이터베이스(Single View Database)로 보게 됨. 따라서 데이터와 사용자가 증가하면 어플리케이션의 수정 없이 기존 시스템에 노드만 추가하고 데이터를 재분배하면 시스템의 성능과 용량을 일정하게 유지 가능.
- 각 노드로 분산되는 파티셔닝을 어떻게 디자인 하느냐에 따라 성능 차이가 많이 발생
- 한 노드에서 장애가 발생한다면, 해당 노드에서 서비스 하는 데이터에 대한 별도의 페일오버 메커니즘(고가용성 보장)이 필요해서 가용성을 보장하기 위해 공유 디스크 방식을 이용

Microsoft SQL Server
- 연합(Federated) 데이터베이스 형태로 여러 노드로 확장할 수 있는 기능을 제공
- 디스크를 공유하지 않는 독립된 서버에서 실행되는 서로 다른 데이터베이스들 간의 네트워크를 통한 논리적인 결합을 제공
- 데이터는 관련된 서버들로 수평적으로 분할되며, 테이블을 논리적으로 분리해 물리적으로는 분산된 각 노드에 생성하고
- 각 노드의 데이터베이스 인스턴스 사이에 링크를 구성한 후
- 모든 파티션에 대해 UNION ALL을 이용하여 논리적인 싱글 뷰(DVP, Distributed Partitioned View)를 구성하는 방식

이 구성의 가장 큰 문제점은 DBA나 개발자가 파티셔닝 정책에 맞게 테이블과 뷰를 생성해야 하고, 전역 스키마(Global Schema) 정보가 없기 때문에 질의 수행을 위해 모든 노드를 액세스해야 한다는 점이다. 노드의 개수가 작으면 간단하게 구성할 수 있지만, 노드가 많아지거나 노드의 추가/삭제가 발생하는 경우 파티션을 새로 해야 하는 문제도 따른다. 또한 페일오버에 대해서는 별도로 구성해야 하며, SQL Server에서도 다음과 같은 페일오버 메커니즘을 제공하지만, Active-Active 가 아닌 Active-Standby(고가용성을 제공하기 위해, 서버나 시스템을 이중화하는 방법 Active Node와 Stand Node가 있어서 활성 노드의 장애를 대기하다가 장애가 일어났을때, Stand Node를 Active Node 의 역할로 대체한다) 방법을 사용하고 있다.
MySQL
MySQL 클러스터는 무공유 구조에서 메모리(최근에는 디스크도 제공) 기반 데이터베이스의 클러스터링을 지원하며, 특정한 하드웨어 및 소프트웨어를 요구하지 않고 병렬 서버구조로 확장 가능하다(유연함).

- 관리 노드: 클러스터를 관리하는 노드로 클러스터 시작과 재구성 시에만 관여
- 데이터 노드: 클러스터의 데이터를 저장하는 노드
- MySQL 노드: 클러스터 데이터에 접근을 지원하는 노드
MySQL의 특징
- 데이터 노드 간에 별도의 네트워크를 구성하여 fault-tolerance를 제공하고, 고가용성 달성
- 디스크 기반의 클러스터링 제공
- 인덱스가 생성된 컬럼은 기존과 동일하게 메모리에서 유지되지만, 인덱스를 생성하지 않은 컬럼은 디스크에 저장됨
- 디스크에 저장된 데이터(인덱스를 생성하지 않은 컬럼)와 JOIN 연산을 수행할 경우 성능이 좋지 않기 때문에 애플리케이션 개발 시 주의해야함
- 디스크에 저장된 데이터라도 인덱스로 구성된 칼럼이 메모리에 있기 때문에 데이터의 크기와 메모리 크기를 고려하여 인덱스 생성과 클러스터의 참여하는 장비의 메모리를 산정해야함
- 파티셔닝은 LINEAR KEY 파티셔닝만 사용가능
- 클러스터에 참여하는 노드(SQL 노드, 데이터 노드, 매니저를 포함) 수는 255로 제한, 데이터 노드는 최대 48개까지
- 트랜잭션 수행 중에 롤백(Rollback)을 지원하지 않음
- 롤백해야 하는 경우, 전체 트랜잭션 이전으로 롤백해야 함..(주의)
- 하나의 트랜잭션에 많은 데이터를 처리하는 경우 메모리 부족 문제가 발생할 수 있음
- 여러 개의 트랜잭션으로 분리해 처리하는 것이 좋음
- 칼럼명 길이는 31자, 데이터베이스와 테이블명 길이는 122자까지로 제한
- 데이터베이스 테이블, 시스템 테이블, 블롭(BLOB) 인덱스를 포함한 메타데이터(속성정보)는 20,320 개까지만 가능
- 클러스터에서 생성할 수 있는 테이블 수는 최대 20,320 개
- 한 로우(row)의 최대 크기는 8KB (BLOB 를 포함하지 않은 경우)
- 테이블의 키는 32개가 최대
- 모든 클러스터의 기종은 동일해야 함
- 운영 도중에 노드를 추가/삭제할 수 없음
- 디스크 기반 클러스터인 경우 tablespace의 개수는 2^32 개
- tablespace당 데이터 파일의 개수는 2^16(65,535) 개
- 데이터 파일의 크기는 32GB 까지 가능하다.
중요하다.
NoSQL
- Google BigTable
- Amazon SimpleDB
- Microsoft SSDS
NoSQL은 key 와 value의 형태로 자료를 저장하고, 빠르게 조회할 수 있는 자료구조를 제공하는 저장소임. 전통적인 RDBMS의 장점이라고 할 수 있는 복잡한 Join 연산 기능은 지원하지 않지만 대용량 데이터와 대규모 확장성을 제공함.
Google BigTable
- Data Model
- multi-dimension sorted hash map을 파티션하여 분산 저장하는 저장소
- 테이블 내의 모든 데이터는 row-key 의 사전적 순서로 정렬/저장
- row는 n개의 column-family를 가짐, column-family에서는 column-key, value, timestamp의 형태로 데이터를 저장
- 하나의 row-key, column-family 내에 저장된 데이터는 column-key의 사전적 순서로 정렬
- 따라서 BigTable에 저장되는 하나의 데이터(map)의 키 값 또는 정렬 기준은 "rowkey+columnkey+timestamp"가 됨
- 테이블의 파티션은 row-key를 이용하며, 분리된 파티션은 분산된 노드에서 서비스하도록 하고, 분리된 파티션을 Tablet이라고 하며, 한 Tablet의 크기는 보통 100 ~ 200 MB임
- Fail Over
- 빅테이블의 Master가 장애가 발생한 노드에 대해서 서비스되던 Tablet을 다른 노드로 재할당
- 재할당 받은 노드는 GFS에 저장된 변경 로그 파일, 인덱스 파일, 데이터 파일 등을 이용하여 데이터 서비스를 위한 초기화 작업을 수행 후 데이터 서비스를 수행
- 빅테이블은 공유 디스크 방식이며, 공유 저장소로 구글에서 개발된 분산 파일 시스템을 이용하고 있어 모든 노드가 데이터, 인덱스 파일을 공유하고 있음
- 빅테이블의 SPOF(Single Point Of Failure)는 마스터임, 시스템 내에서 전체 시스템이 마비될 가능성을 가진 하나의 요소고, 이 요소가 작동하지 않으면 전체 시스템이 영향을 받아 서비스 중단이 발생함.
- 빅테이블은 분산 락(lock) 서비스를 제공하는 Chubby를 이용하여 Master를 계속 모니터링하다가 마스터에 장애가 발생하면 가용한 노드에 마스터 역할을 수행하도록 함
- Chubby는 자체적으로 fault-tolerance를 지원하는 구조이기 때문에 절대로 장애가 발생하지 않음
- 데이터 저장소는 파일 시스템, Map & Reduce 컴퓨팅 클러스터와 동일한 클러스터 위에 구성됨
- 실시간 서비스 뿐만 아니라 대용량 데이터의 분석 처리에 적합하도록 구성됨

- App Engine
- 어플리케이션의 데이터 저장소를 제공함
- 빅테이블을 이용하며 사용자에게 직접 빅테이블의 API, 데이터 모델의 API를 공개하지 않고 추상화를 통해 제공
- 사용자 테이블을 생성할 경우 빅테이블의 테이블 별로 생성되는 것이 아니라 빅테이블의 특정 테이블의 한 영역만 차지
- 별도의 사용자 정의 인덱스를 제공하지 않지만, AppEngine 에서 수행하는 쿼리를 자동으로 분석해서 인덱스를 생성해줌
- 여기서 생성한 인덱스도 빅테이블의 특정 테이블 또는 테이블 내의 컬럼(column)으로 저장됨
Amazon SimpleDB
웹 어플리케이션에서 사용하는 데이터의 실시간 처리를 지원하는 데이터 서비스 플랫폼임. 보통 다른 아마존의 플랫폼 서비스와 함께 사용되고, 하나의 데이터에 대해 여러 개의 복제본을 유지하는 방식으로 가용성을 높임. 이 경우 복제본 간의 consistency를 고려해야 하며, SimpleDB에서는 Eventual Consistency 정책을 취함. Eventual Consistency는 트랜잭션 종료 후에 데이터는 모든 노드에 즉시 반영되지 않고 초 단위로 지연되어 동기화 됨.
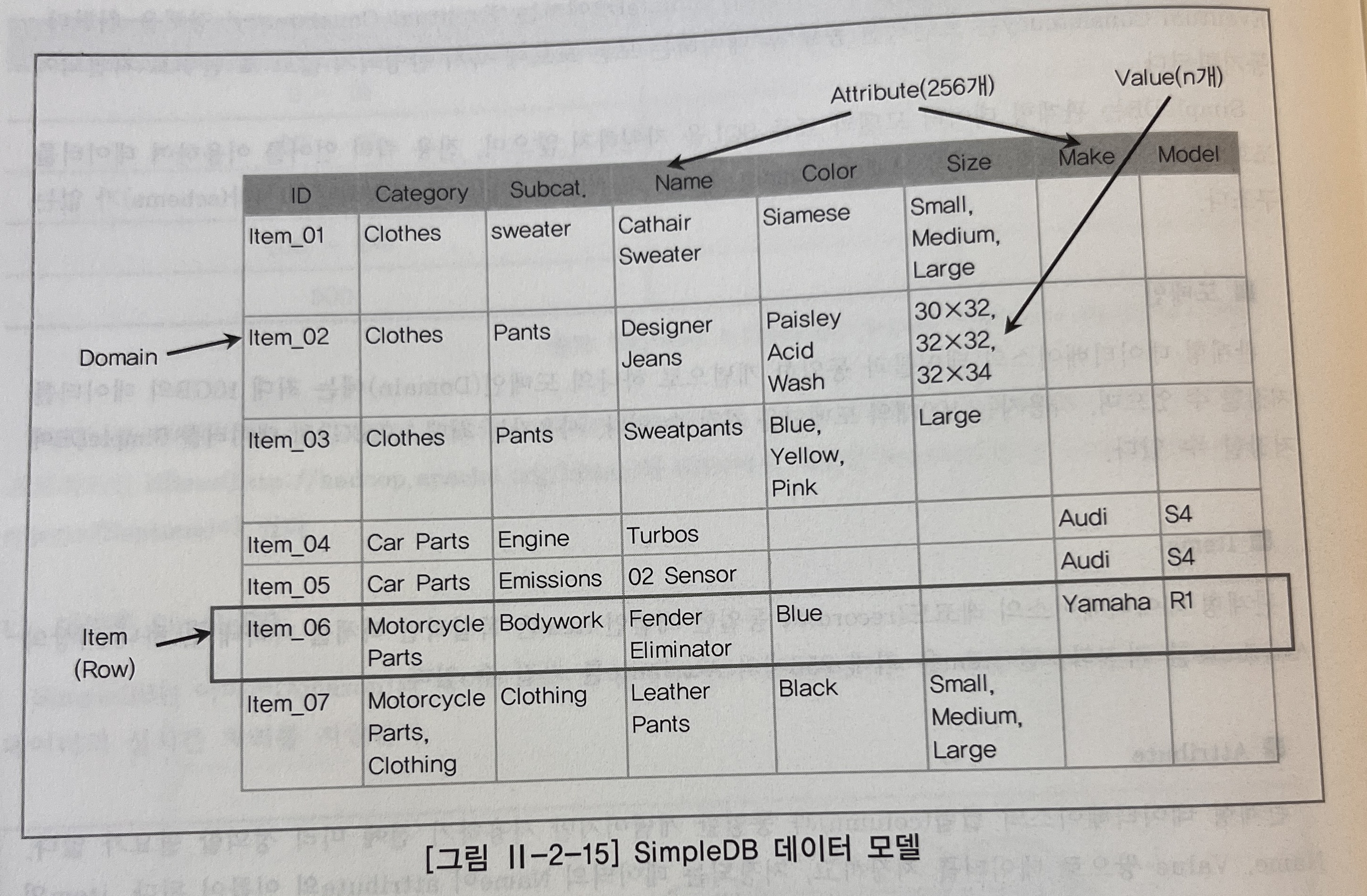
- 관계형 데이터 모델과 표준 SQL을 지원하지 않음
- 전용 쿼리 언어를 사용해 데이터 조회
- Data Model
- Domain: 테이블과 동일한 개념으로 하나의 도메인(Domain)에 최대 10GB의 데이터를 저장가능, 사용자는 100개의 도메인을 가지고, 최대 1000GB의 데이터를 SimpleDB에 저장 가능.
- Items: 레코드와 동일한 개념인 item은 독립적인 객체를 나타내고, 하나 이상의 Attribute를 가짐. 한 item은 최대 256개의 Attribute를 가짐.
- Attribute: 관계형 데이터베이스의 컬럼과 동일한 개념이지만 사용하기 전에 미리 정의할 필요가 없음. Name, Value 쌍으로 데이터를 저장하고, 저장되는 데이터의 Name이 attribute의 이름이 됨. item의 특정 attribute에는 여러 개의 값을 저장할 수 있음
- 여러 도메인에 걸친 쿼리는 허용되지 않고, 한 번에 하나의 도메인에 대해서만 쿼리를 수행해야 한다
- 1+N(mast-slave) 관계의 데이터 모델을 갖는 두 개의 도멩니으로부터 데이터를 조회할 경우 쿼리가 여러 번 수행돼야 하는 단점이 있음
- <, > 의 연산에 대해서 value에 특정 데이터가 많으면 쿼리 성능이 좋지 않음
- SOAP 또는 REST 프로토콜을 사용하여 SimpleDB 를 이용가능함
- CreateDomain: 도메인을 생성함
- DeleteDomain: 도메인을 삭제함
- ListDomains: 모든 도메인의 목록을 가져옴
- PutAttributes: Item을 생성하고 Attribute에 값을 추가함
- DeleteAttributes: Attribute 값을 삭제함
- GetAttributes: Attribute의 값을 조회함
- Query: 조건에 맞는 여러 개의 item을 조회함. 한 번의 쿼리는 최대 5초 이내에 수행되어야 하며, 쿼리 결과로 받을 수 있는 최대 item 수는 256개임
Microsoft SSDS
- 고가용성을 보장
- 데이터 모델은 컨테이너, 엔티티로 구성되어 있음
- 하나의 컨테이너에 여러 종류의 엔티티를 저장 가능
- 하나의 엔티티는 여러 개의 property를 가짐
- property는 name-value 쌍으로 저장됨
- SSDS 를 이용하여 어플리케이션 개발 시 관련 정보를 하나의 컨테이너에 저장함

이런 방식의 컨테이너는 여러 컨테이너가 생성될 수 있고 컨테이너 단위로 여러 노드에 분산되어 관리 된다. 쿼리는 하나의 컨테이너만을 대상으로 함. 컨테이너의 생성/삭제, 엔티티의 생성/삭제/조회, 쿼리 등의 API를 제공하고 SOAP/REST 기반의 프로토콜을 지원함.
'AI > ADP' 카테고리의 다른 글
| [ADP] 2장 데이터 처리 기술의 이해 - 데이터 처리 기술, 병렬 쿼리 시스템 (0) | 2024.07.20 |
|---|---|
| [ADP] 2장 데이터 처리 기술의 이해 - 데이터 처리 기술, MapReduce (0) | 2024.07.20 |
| [ADP] 2장 데이터 처리 기술의 이해 - 데이터 처리 프로세스, 대용량 비정형 데이터 처리 (0) | 2024.07.16 |
| [ADP] 2장 데이터 처리 기술의 이해 - 데이터 처리 프로세스, 데이터 연계 및 통합 기법 요약 (0) | 2024.07.16 |
| [ADP] 2장 데이터 처리 기술 이해 - 데이터 처리 프로세스, EAI(Enterprise Application Integration) (0) | 2024.07.16 |



