
- 분류 전체보기 (268)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- preprocessing
- Entity Set
- 리눅스 기초
- Entity
- Class
- OOP
- systemd
- Binary Search
- Unity
- Reference Type
- External Scheme
- 셀레니움
- python
- BFS
- X.org
- Polymolphism
- dbms
- 리눅스 마스터 1급
- selenium
- Operator
- 자바
- Physical Scheme
- Mac
- 백준
- X윈도우
- Java
- 리눅스
- literal
- zsh
- Inheritance
- Today
- Total
Byeol Lo
5.7 Operating-System Examples 본문
Linux, Window, Solaris의 스케줄링을 살펴보자(보통 그냥 스케줄링이라고 하면 일반적인 의미에서 process scheduling 용어를 말함). 또한 솔라리스와 윈도우 시스템에서 kernel threads의 스케줄링 및 리눅스 스케줄러에서 task scheduling 도 볼 것이다.
5.7.1 Example: Linux Scheduling
리눅스는 UNIX 스케줄링 알고리즘을 변형하여 사용한다. 하지만 이 알고리즘은 SMP 아키텍처를 고려하여 설계된게 아니기 때문에 다중 프로세서 시스템을 충분히 지원하지 못했다. 리눅스 커널 버전 2.5 에서는 스케줄러가 개편되면서 task 수에 상고나없이 상수 시간에 작동하는 O(1) 스케줄링 알고리즘이 포함되었고, SMP 시스템을 위해 processor affinity와 load balancing 을 고려한 추가 지원이 제공되었다. O(1) 스케줄링은 많은 컴퓨터에서 흔한 대화형 프로세스에 대한 응답 시간이 저하되었는데, 커널 2.6 개발중에 스케줄러는 다시 개정되며 2.6.23에서 CFS(Completely Fair Scheduler)가 리눅스의 기본 스케줄링 알고리즘으로 채택되었다.
#include <pthread.h>
#include <stdio.h>
#define NUM_THREADS 5
int main(int argc, char *argv[])
{
int i, policy;
pthread_t tid[NUM_THREADS];
pthread_attr_t attr;
pthread_attr_init(&attr);
if (pthread_attr_getschedpolicy(&attr, &policy) != 0)
fprintf(stderr, "Unable to get policy.∖n");
else {
if (policy == SCHED_OTHER)
printf("SCHED OTHER∖n");
else if (policy == SCHED_RR)
printf("SCHED RR∖n");
else if (policy == SCHED_FIFO)
printf("SCHED FIFO∖n");
}
if (pthread_attr_setschedpolicy(&attr, SCHED_FIFO) != 0)
fprintf(stderr, "Unable to set policy.∖n");
for (i = 0; i < NUM_THREADS; i++)
pthread_create(&tid[i], &attr, runner, NULL);
for (i = 0; i < NUM_THREADS; i++)
pthread_join(tid[i], NULL);
}
void *runner(void *param)
{
pthread_exit(0);
}
리눅스 시스템에서는 scheduling classes에 기반하여 스케줄링이 이루어진다. 각 클래스는 특정 우선순위(정수)가 할당되며, 다양한 스케줄링 클래스를 사용함으로써 커널은 시스템과 해당 프로세스의 필요에 따라 다양한 스케줄링 알고리즘을 수용할 수 있다. 표준 리눅스 커널은 두 가지 scheduling class를 구현한다.
- CFS 스케줄링
- Real-Time 스케줄링
두 클래스를 살펴보자.
Nice
CFS 스케줄러는 시간 양자(time quantum)의 길이에 상대적인 우선순위 값을 엄격한 규칙을 사용하기 보다는 CPU 처리 시간의 비율을 할당한다. 이 비율은 task(프로세스)에 할당되어 있는 nice 값에 기반하여 계산되고 nice 값은 -20 ~ 19의 정수 값을 가지며, 우선순위와 반비례하는 관계를 가진다. 기본적으로 이 값은 0이며, 0 에서 10을 증가시키면 상대적으로 낮은 우선순위를 가지며 다른 작업에게 "친절"하게 양보를 한다는 개념을 가지고 있다.
Targeted Latency
CFS 스케줄러는 Nice 값 외에도 목표 지연 이라는 값이 있는데, 만약에 20 milliseconds가 targeted latency라면 최소 이 20 milliseconds 안에 실행가능한 모든 프로세스들이 "최소" 한 번씩은 CPU를 점유해서 실행시켜주어야 한다는 것이다. 특징으로는 이는 고정된 시간 할당량을 사용하는 방식보다 더 유연하고 공정하게 CPU 시간을 분배할 수 있게 해준다. 작업의 수가 증가하면 목표 지연은 더 길어질 수 있으며, 이를 통해 모든 작업이 공정하게 실행될 수 있도록 보장하게 된다.
Virtual Run Time
CFS 스케줄러는 또 각 작업의 실행 시간을 기록하기 위한 변수인 vruntime 을 사용하여 실행시간을 유지한다. 가상 실행 시간에서 감쇠 계수라는게 있는데, 작업의 우선순위가 이 감쇠계수와 연관이 깊다.
일반 우선순위(nice 값이 0인) 작업의 경우, 가상 실행 시간은 실제 물리적 실행 시간과 동일하다. 만약 우선순위가 기본 우선순위를 가진 작업이 200밀리초 동안 실행되면, 그 vruntime도 200밀리초가 되지만, 우선순위가 상대적으로 낮은 작업이 200밀리초 동안 실행되면 그 vruntime은 200밀리초보다 높아집니다. 마찬가지로, 우선순위가 상대적으로 높은 작업이 200밀리초 동안 실행되면 그 vruntime은 200밀리초보다 낮아진다. 따라서 작업의 우선순위가 vruntime의 감쇠계수와는 반비례 관계임을 볼 수 있다.
- 우선 순위 낮음 → vruntime의 감쇠 계수가 늘어남 → vruntime 이 늘어남
- 우선 순위 높음 → vruntime의 감쇠 계수가 줄어듦 → vruntime 이 줄어듦
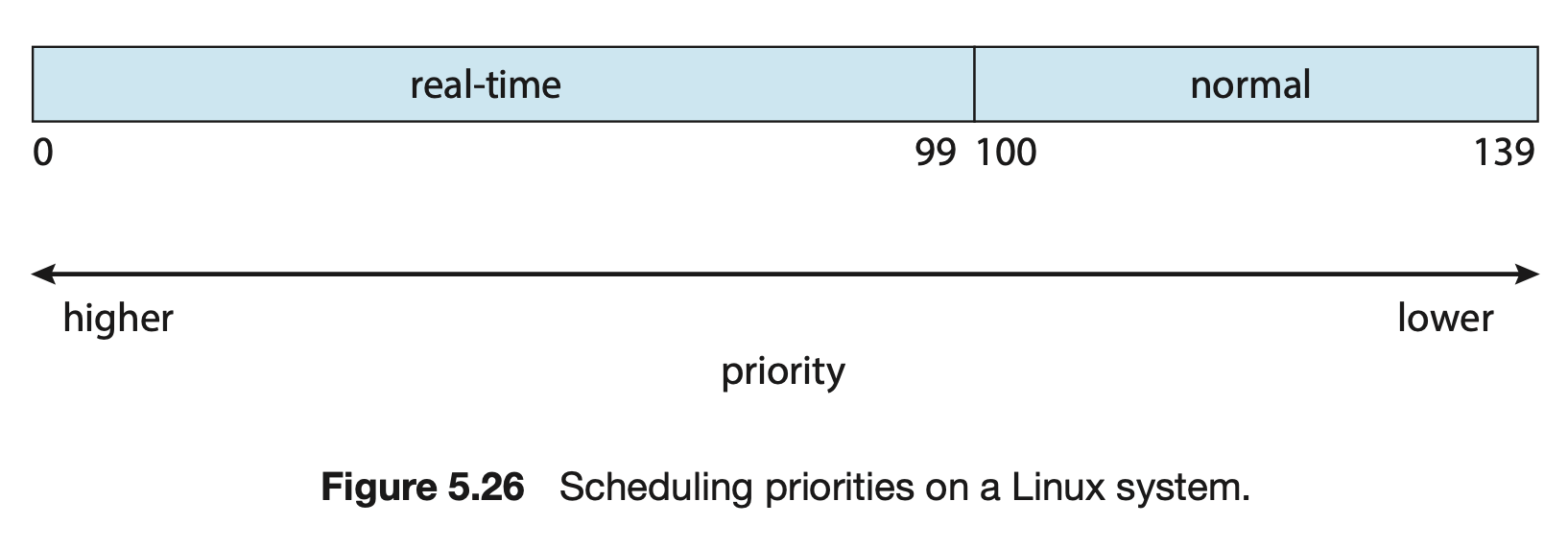
이제 CFS의 모든 개념을 알았으니 동작 방법을 살펴보자. Linux에서 priority는 보통 0부터 139까지의 값을 가지며, 0부터 99의 값은 real-time task에게 할당되는, 그리고 일반적인 작업은 100부터 139의 값을 가지게 된다. 숫자가 낮은게 높은 우선순위를 가지게 되며, 일반적인 작업의 Priority는 Nice 값에 따라 결정이 되며, 낮은 nice 값의 프로세스는 높은 priority를 가지게 된다. 따라서 nice가 -20 인 애는 위 그림에서 100에 해당하며, nice가 19인 애는 139에 할당되게 된다.
CFS는 또 load balancing을 위해 복잡한 기술을 사용하고 있다. 또한 여기서 NUMA를 고려하면서 스레드의 이동을 최소화(processor affinity 때문) 한다. 기본적으로 load balancing을 위해서 스레드의 우선순위, CPU의 평균 이용률을 따져서 "부하(load)" 라는 것을 정의하고, 이에 따라 큐에 들어 있는 모든 스레드들의 load sum을 척도로 모든 큐들의 부하를 관리하게 된다.

스레드를 이동시킬 때 캐시를 free 시켜줘야 하는데, NUMA에서는 더 긴 메모리 액세스 패널티를 초래할 수 있다. 이 문제를 위해 위의 NUMA 구조를 보자. CPU 코어들의 집합이 도메인으로 나와 있고 도메인에 L2 캐시도 보인다. 일반적으로 코어 자체에서 L1 캐시도 가지고 있지만, L2의 캐시를 별도로 준비하여 이 L2 캐시를 동시에 쓰는 코어0, 코어1의 쌍이 서로 부하 분산을 분산 시킬 수 있는 범위가 된다. 즉, core0이 큐에 너무 많은 스레드가 할당되었을때, 부하 분산을 위해 core1에게 옮길 수 있다는 소리이다. 그 상위의 L3 캐시도 그러면 동일한 목적을 위해 존재하게 되는 것이다. 즉, 캐시 메모리를 통해서 서로간의 부하 분산을 위해 processor의 queue간의 thread 이동을 관리한다.
그래서 구조를 보면 알다시피 가장 낮은 수준 캐시를 공유하는 프로세서들 간에 먼저 load balancing을 하고, 이마저도 안되면, 그 상위에서 이 문제를 다루는 식이다. 근데 이렇게 상위로 계속 올라가는 것은 심각한 부하가 발생했을 때의 경우라 굉장히 드문 일이다. 또 이런 일은 CFS는 스레드를 지역 메모리로부터 위의 범위 외의 지역으로 더 멀리 이동시킬 경우이므로 비용이 드는 일(memory stall)이기 때문에 L3 보다 초과되는 이동은 하지 않는다.
5.7.2 Examples: Windows Scheduling & 5.7.3 Examples: Solaris Scheduling은 추후에 하겠다.
'OS > OS Design' 카테고리의 다른 글
| 6.1 Synchronization Tools (0) | 2024.05.18 |
|---|---|
| 5.8 Algorithm Evaluation (0) | 2024.05.18 |
| 5.6 Real-Time CPU Scheduling (0) | 2024.05.16 |
| 5.5 Multi-Processor Scheduling (0) | 2024.05.16 |
| 5.4 Thread Scheduling (1) | 2024.05.15 |


