
- 분류 전체보기 (268)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Mac
- Binary Search
- Polymolphism
- External Scheme
- literal
- Operator
- Class
- 자바
- 백준
- Java
- 셀레니움
- 리눅스 기초
- zsh
- selenium
- preprocessing
- 리눅스
- X.org
- Entity
- Inheritance
- Physical Scheme
- Reference Type
- Entity Set
- X윈도우
- BFS
- systemd
- dbms
- OOP
- python
- Unity
- 리눅스 마스터 1급
- Today
- Total
Byeol Lo
5.5 Multi-Processor Scheduling 본문
지금까지는 단일 처리 코어만 봤다. 현재는 여러 처리 코어(다중 코어) 시스템이 대다수이기 때문에 여러 스레드가 병렬로 실행될 수 있다. 이는 스케줄링이 매우 복잡해지는 단점이 있지만 그만큼 빠르게 처리할 수 있기 때문에 선호된다.
- Multicore CPUs
- Multiheaded cores
- NUMA systems
- Heterogeneous multiprocessing
위의 다양한 아키텍처에서 다중 프로세서의 스케줄링을 살펴보자.
5.5.1 Approaches to Multiple-Processor Scheduling
멀티 프로세서 시스템에서 CPU 스케줄링의 접근법은 다양하게 있지만, 그 중에 한가지는 모든 스케줄링의 결정, I/O 처리 및 기타 시스템 활동을 단일 프로세서인 master server가 처리하는 것이다.
다른 프로세서들은 사용자 코드만 실행하지만 이런 asymmetric multiprocessing 은 단순해서 하나의코어만 시스템 데이터 구조에 접근하므로 데이터공유의 필요성이 줄어들게 된다. 하지만 이 접근 방식의 단점은 마스터 서버가 잠재적인 병목 지점이 되어서 전체 성능이 저하될 수 있다.
멀티프로세서를 지원하는 표준 접근법은 Symmetric Multiprocessing (SMP)로 각 프로세서가 자체적으로 스케줄링을 한다. 스케줄링은 각 프로세서의 스케줄러가 ready queue를 검사하고 실행할 스레드를 선택하는 방식으로 진행된다. 이는 스케줄링 가능한 스레드를 구성하는 두 가지 가능한 전략을 제공한다.
- 모든 스레드가 공통 준비큐에 있을 수 있다.
- 각 프로세서가 자체적인 스레드 큐를 가질 수 있다.

위 그림처럼 a는 공유 준비 큐에서 경합 상태가 발생할 수 있으므로 두 개의 별도 프로세서가 동일한 스레드를 선택하지 않도록 하고, 스레드가 큐에서 사라지지 않도록 해야한다. 이 경합 상태를 방지하기 위해서는 lock을 사용해야 하지만 6장에 나올 예정이다. lock은 queue에 대한 모든 접근이 lock 소유권을 요구하므로 높은 경쟁을 야기하며, 공유 큐에 접근하는 것은 병목, 혼잡이 일어날 수 있다.
b는 각 프로세서가 자체 실행 큐에서 스레드를 스케줄링하도록 하여서 공유 실행 큐와 관련된 잠재적 성능 문제를 겪지 않는다. 따라서 SMP를 지원하는 시스템에서 가장 일반적인 접근 방식이다. 추가로 5.5.4에서 프로세서별 개인 실행 큐를 갖는 것은 캐시 메모리의 효율성을 증가시킬 수 있다. 프로세서 별로 실행 큐에서는 다양한 크기의 작업 부하가 가장 큰 문제이다. 하지만 우리는 균형 알고리즘을 사용하여 모든 프로세서 간에 작업 부하를 평등하게 할 수 있고, 거의 모든 운영체제가 SMP를 통해 이 문제들을 논의하게 된다.
5.5.2 Multicore Processors
Symmetric Multi-Processing 여러 물리 프로세서를 통해 프로세스를 병렬로 실행한다. 지금은 더 발전하여 여러 개의 컴퓨팅 코어를 동일한 칩에 박아서 다중 코어 프로세서(multicore processor)를 만든다. 운영 체제는 각 코어는 개별적인 논리 CPU로 인식하게 되고, 그만큼 더 빠르고, 여러 개의 프로세스를 실행시킬 수 있다. 하지만 이렇게 장점만 있는게 아니다.
SMP는 여러 코어를 가졌기 때문에 프로세서에서는 각 코어가 동시에 메모리에 액세스 할 수 있는 상황이 발생할 수 있고, 또한 각 프로세서가 메모리에 접근할 때 데이터를 기다리는 시간이 발생하는데, 이는 프로세서가 매우 빠르게 동작해서 이 속도가 메모리의 동작 속도보다 훨씬 빠르기 때문에 프로세서가 메모리에 액세스할 때 램에 완전히 데이터가 업로드 될 때까지 기다려야 하는 시간이 발생할 수 있다는 것이다. 이를 메모리 지연(memory stall) 이라고 한다. 이런 메모리 지연은 그 상황에서만 발생하는게 아니라 캐시 미스(cache miss)로 인해서도 memory stall이 생길 수 있다(cache miss는 메모리에서 데이터를 가져오기도 전에 캐시에 접근해서 접근할 데이터가 없는 것).

이(memory stall)를 해결하기 위해서 multithread를 코어들에게 할당시켜서 하나의 하드웨어 스레드가 메모리를 기다리는 동안 다른 스레드로 전환시킬 수 있도록 한다. 운영체제의 관점에서는 하드웨어 thread는 자체적인 아키텍처 상태(instruction pointer, register set)를 유지하는데, 이는 스레드가 논리적 CPU로 인식 될 수 있는 이유이며, 소프트웨어 스레드를 실행할 수 있는 독립적인 실행 단위로 동작할 수 있는 이유이다. 이렇게 하나의 코어에 multithread를 할당시키는 것을 CMT라고 하며, CMT(chip multithreading)은 하나의 물리적인 프로세서에서 여러 개의 하드웨어 스레드를 지원하는 방식을 나타낸다.

Intel에서는 하이퍼스레딩(hyper-threading) 또는 동시 멀티스레딩(SMT)이라는 용어를 사용하여 여러 하드웨어 스레드를 단일 처리 코어에 할당하는 것을 설명한다. 또 다른 오라클 Sparc M7 프로세서는 코어 당 8개의 스레드를 지원한다.

일반적으로 프로세싱 코어를 멀티스레드화 하는 방법에는 두 가지가 있다. coarse-grained과 fine-grained multithreading 이다. coarse-grained multithreading의 경우에 스레드는 memory stall 같은 긴 지연이 발생할때까지 코어에서 실행된다. 이런 문제로 인해서 코어는 다른 스레드로 전환하여 실행을 시작해야 하고 이는 스레드 간 높은 전환 비용을 요구하게 된다. 이는 다른 프로세서 코어에서 실행을 시작하기 전에 명령 pipeline을 비워야 하는 비용이다. 새로운 스레드가 실행을 시작하면 해당 스레드는 자신의 명령을 pipeline에 채워야 하고 이는 명령어를 처리하는 단계적인 과정으로 ram에 어떤 부분을 지칭하는 거기도 한다.
하지만 fine-grained multithreading은 스레드 간 전환을 명령 사이클의 경계에서 더 세밀한 수준으로 수행하기 때문에 fine-grained multithreading의 아키텍처 설계에는 스레드 전환을 위한 논리가 포함되어 있고 스레드 간의 전환 비용이 줄어들게 된다.
아키텍처에서 하나의 물리 코어는 여러 개의 스레드를 가질 수 있고, 하나의 코어가 한 번에 하나의 스레드만 실행할 수 있다. 코어 내의 자원이 여러 하드웨어 스레드 사이에서 공유되기 때문에 이 구조에서는 운영체제가 각 하드웨어 스레드에 실행할 소프트웨어 스레드를 선택하는데 두 가지 수준의 스케줄링이 필요하다.
첫 번째 수준에서는 운영 체제가 각 하드웨어 스레드(논리적 CPU)에 대해 실행할 소프트웨어 스레드를 선택하는 스케줄링 결정을 내리는 것이다. 이 결정은 이 장의 처음에 언급했다. 이 수준의 스케줄링에서는 5.3절에서 설명된 것과 같이 어떤 스케줄링 알고리즘을 선택할 수 있냐의 고민이었다. 두 번째 수준의 스케줄링은 각 코어가 어떤 하드웨어 스레드를 실행할지 결정하는 것이다.
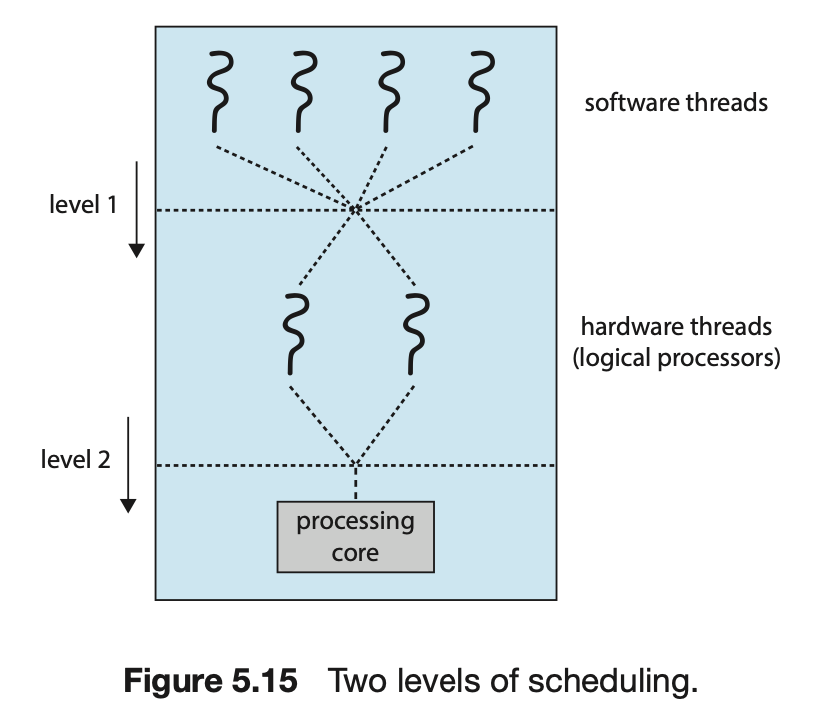
간단한 round-robin 부터 어떤 아키텍처는 0부터 7까지의 동적 긴급도를 할당하여 이 값으로 어떤 스레드를 먼저 처리할 것인지도 결정하는 아키텍처도 있다.
이 두 수준의 스케줄링은 서로 베타적이진 않는데, 실제로 운영 체제 스케줄러(level 1)가 프로세서 리소스의 공유를 인식하면 더 효과적인 스케줄링 결정을 내릴 수 있을 것이다. 예를 들어서 CPU에 두 개의 처리 코어가 있고 각 코어에는 두 개의 하드웨어 스레드가 있는 경우를 가정해보자. 두 개의 소프트웨어 스레드가 실행 중이라면, 이들은 동일한 코어에서 실행될 때는 프로세서 리소스를 공유해야 하므로 별도의 코어에서 실행될 때보다 느리게 진행될 가능성이 높으며, 운영 체제가 프로세서 리소스 공유 수준을 인지하고 있다면, 리소스를 공유하지 않는 논리적 프로세서에게 스레드를 스케줄링 하도록 하여 더 빠르게 실행되도록 할 수 있다(그래서 0, 2, 4, 6, 1, 3, 5, 7의 논리 프로세서 순으로 스레드 할당이 되는 것).
5.5.3 Load Balancing
SMP에서 여러 프로세서의 이점을 활용하여 작업 부하를 나누는게(load balancing) 중요하다. 그렇지 않다면 유휴 상태에 빠지기 쉽고, 다른 프로세서는 높은 작업 부하를 가지게 되면서 이 프로세서를 기다리는 준비 큐가 늘어나게 될 것이다. 그래서 가장 중요한 것은 어떻게 배분하냐는 것이다.

위의 사진에서도 보다시피 이는 코어마다 준비 큐를 가지고 있기 때문에 일어나는 일이며, 코어들이 서로 공유하는 큐를 가진다면 이러한 일이 발생하지 않을 것이고 이런 문제점도 애초에 고려 할 필요가 없을 것이다. load balancing(작업 부하 균형)을 위해서는 푸시 이전(push migration)과 풀 이전(pull migration)이 있다.
push migration은 특정 작업이 주기적으로 각 프로세서의 부하를 확인하고 불균형을 발견했을시 즉시 과부하된 프로세서에서 유휴 상태나 적게 바쁜 프로세스로 스레드를 이동하여 부하를 고르게 분산시키는 것이다. pull migration은 유휴 상태의 프로세서가 바쁜 프로세서에서 대기 중인 작업을 끌어올리는 것이다.
두 방법은 꼭 하나만을 사용하는게 아니라 둘 다 사용 할 수 있으며 load balancing을 위해 병렬적으로 구현된다. load balancing은 다양한 의미를 가질 수 있는데, 한 관점은 모든 큐가 대략적으로 동일한 수의 스레드를 가지고 있는 것, 다른 관점은 균형이 모든 큐에 있는 스레드 우선순위를 동등하게 분산하는 것으로 볼 수 있다. 전략, 상황에 따라 유동적으로 적용시키면 된다.
5.5.4 Processor Affinity

설명을 위해 1.3절의 사진을 들고 왔다. 특정 프로세서에서 스레드가 실행되고 있는 경우 cache 에는 어떤 일이 발생하는지 보자. 스레드가 최근에 액세스한 데이터는 해당 프로세서의 cache에 저장된다. 결과적으로 스레드에 의한 연속적인 메모리 액세스는 캐시 메모리에서 처리될 가능성이 높아진다(이를 warm cache 라고 함).
이제 스레드가 다른 프로세서로 마이그레이션 되는 경우를 생각해보자. 예를 들어 부하 분산으로 인해 첫 번째 프로세서의 캐시 메모리 내용은 무효화(free)되어야 하며, 두 번째 프로세서의 캐시는 다시 채워져야 한다. 캐시를 무효화하고 채우는 비용이 높기 때문에 SMP 지원을 갖춘 대부분의 운영 체제는 스레드를 한 프로세서에서 다른 프로세서로 migration 하려고 하지 않고, 대신 스레드를 동일한 프로세서에서 실행하고 캐시의 이점을 활용하려고 노력한다. 이를 processor affinity(프로세서 유연성)라고 한다.
스케줄링에 사용할 수 있는 스레드의 큐를 구성하는 두 가지 전략은 processor affinity에 영향을 미친다. common ready queue 방식을 채택하면 어떤 processor에서도 스레드가 실행될 수 있다. 따라서 스레드가 새로운 프로세서에서 스케줄 되면 해당 프로세서의 캐시를 다시 채워야 한다. 반면에 개별 프로세서 마다 준비 큐를 유지하면 스레드가 항상 동일한 프로세서에서 스케줄 되므로 warm cache의 내용을 활용할 수 있다. 그래서 기본적으로 개별 프로세서의 준비 큐들은 processor affinity를 무료로 제공한다.
processor affinity는 여러 형태를 가질 수 있는데, 운영 체제가 프로세스를 동일한 프로세서에서 실행하도록 시도하는 규정이 있지만 그런 보장을 하지 않는 경우에 soft affinity라고 부른다. 여기서 운영 체제는 프로세스를 하나의 프로세서에 유지하려고 노력하지만 load balancing 중에 프로세스가 프로세서 사이를 이동할 수 있다는 것을 알 것이다. 반면에 일부 아키텍처에서는 hard affinity라고 해서 프로세스가 실행될 프로세서 하위 집합을 지정할 수 있다. 많은 시스템은 soft affinity와 hard affinity를 모두 제공한다.
시스템의 주 메모리 아키텍처도 프로세서 어피니티 문제에 영향을 줄 수 있는데,

NUMA(Non-Uniform Memory Access) 아키텍처를 갖춘 시스템에서 각각 자체의 CPU와 로컬 메모리를 볼 수 있는데, 모든 CPU가 하나의 물리적 주소 공간을 공유할 수 있도록 시스템 상호 연결이 허용되지만, CPU는 자체 로컬 메모리에 대한 액세스가 다른 CPU의 로컬 메모리에 대한 액세스보다 빠르다. 운영 체제의 CPU 스케줄러와 메모리 배치 알고리즘이 NUMA를 인식하고 함께 작동한다면, 특정 CPU로 스케줄된 스레드는 CPU가 위치한 곳과 가장 가까운 메모리가 할당될 수 있으며, 이로 인해 스레드는 가능한 최고 속도로 메모리에 액세스 할 수 있다.
load balancing은 종종 processor affinity의 장점을 상쇄시킨다. 스레드를 동일한 프로세서에서 실행하는 장점은 스레드가 해당 프로세서의 캐시 메모리에 이쓴 데이터를 활용할 수 있다는 것이다. 스레드를 한 프로세서에서 다른 프로세서로 이동하여 load balancing을 하면 이러한 이점이 상쇄 된다. 마찬가지로 NUMA 시스템에서 스레드를 프로세서 간에 이동하는 경우에 메모리 액세스 시간이 더 긴 프로세서로 스레드가 이동할 수 있기 때문에 패널티가 발생할 수도 있다. 따라서 부하 분산과 메모리 액세스 시간 최소화 사이에는 자연스러운 균형이 필요하게 된다(trade-off 관계임). 그래서 현대의 다중 코어 NUMA 시스템의 스케줄링 알고리즘은 매우 복잡하다.
5.5.5 Heterogeneous Multiprocessing
이전에 살펴본 것은 SMP로 모든 프로세서가 기능적으로 동일한 일을 수행하는, 목적상 동일한 프로세서였다. 그래서 어떤 스레드이건 간에 모든 코어에서 처리가 될 수 있었다.
모바일 시스템에도 멀티코어 아키텍처가 포함되어 있지만 일부 시스템은 동일한 명령 집합을 실행하는 코어를 사용하면서도 클럭 속도와 전력 관리 측면에서 다양하게 변할 수 있다. 이러한 시스템을 Heterogeneous Multiprocessing(HMP)라고 한다. 5.5.1 절에 설명된 비대칭 멀티프로세싱의 형태가 아니다. 왜냐면 시스템 및 사용자 작업 모두 모든 코어에서 실행될 수 있다. HMP의 의도는 작업의 특정 요구에 따라 특정 코어에 작업을 할당하여 전력 소비를 더 효과적으로 관리하는 것이다.
이런 접근법은 느린 코어들고 빠른 코어들을 묶어서 CPU 스케줄러가 고성능이 필요하지 않지만 더 긴 기간이 필요한 작업을 작은 코어에 할당시켜서 배터리 수명을 늘릴 수 있다. 마찬가지로 더 많은 처리 능력이 필요하지만 더 짧은 시간 동안 실행되는 대화형 어플리케이션은 큰 코어에 할당시켜서 적재적소에 맞게 사용할 수 있다.
'OS > OS Design' 카테고리의 다른 글
| 5.7 Operating-System Examples (0) | 2024.05.17 |
|---|---|
| 5.6 Real-Time CPU Scheduling (0) | 2024.05.16 |
| 5.4 Thread Scheduling (1) | 2024.05.15 |
| 5.3 Scheduling Algorithms (1) | 2024.05.15 |
| 5.2 Scheduling Criteria (0) | 2024.05.14 |


