
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- Polymolphism
- selenium
- 백준
- X윈도우
- Inheritance
- OOP
- literal
- Reference Type
- 리눅스
- Binary Search
- Java
- 셀레니움
- 리눅스 마스터 1급
- Unity
- Entity Set
- Mac
- 리눅스 기초
- X.org
- BFS
- 자바
- preprocessing
- dbms
- python
- Class
- systemd
- zsh
- Entity
- External Scheme
- Operator
- Physical Scheme
- Today
- Total
Byeol Lo
[ADP] 4장 데이터 분석 - Model Evaluation 본문
모델은 전부 학습 데이터들을 가지며 학습 데이터만을 보고 실제로 실생활에 적용되어진다. 하지만 그 전에 test나 validation을 거쳐서 모델들이 정말 실생활에 적용해도 될지 등을 검증하는 것이 있어야 할 것이다. 여기서 훈련에 쓰이는 데이터를 training data, 그 다음 모델의 성과를 검증하기 위해서 test data를 두게 된다(validation data는 보통 hyper parameter이 적절히 되었는지 봄).
만약에 이와 같은 과정을 안거친다면 우리의 training set에서만 굉장히 좋은 모델인 overfitting 문제가 발생하게 된다. 따라서 이를 방지하기 위한 다른 다양한 기법들을 보자.
Hold out
홀드 아웃 방법은 일반적으로 전체 데이터 중 훈련/검증 데이터 두 분류를 통해 모델의 성과를 평가한다. 고전적인 방법이지만 간단하다.
data(iris)
nrow(iris)
set.seed(1234)
idx <- sample(2, nrow(iris), replace = T, prob = c(0.7, 0.3))
trainData <- iris[idx==1,]
testData <- iris[idx==2,]
nrow(trainData)
nrow(testData)sampling 으로 복원 추출을 하면 간단히 수행할 수 있다. 여기서 prob 인자를 통해 비율을 맞춰주면 된다.
K-fold Cross Validation
전체 데이터를 동일한 k개의 서브 데이터 집합으로 분류하고, 번갈아가면서 모든 집합을 검증용 자료를 사용하게 하는 것이다. 따라서 k 번의 반복 측정이 되게 되고, 반복 측정 결과의 평균을 최종 평가로 한다(느린게 단점,, 10-fold면 10번 학습하고 validation 돌리고 해야함).
data(iris)
set.seed(1234)
k = 10
iris <- iris[sample(nrow(iris)), ] # Randomly Shuffle
folds <- cut(seq(1, nrow(iris)), breaks=k, labels=F)
trainData = list(0)
testData = list(0)
for (i in 1:k) {
testIdx <- which(folds==i, arr.ind=T)
testData[[i]] <- iris[testIdx,]
trainData[[i]] <- iris[-testIdx,]
}
head(trainData[[1]]) Sepal.Length Sepal.Width Petal.Length Petal.Width Species
126 7.2 3.2 6.0 1.8 virginica
62 5.9 3.0 4.2 1.5 versicolor
4 4.6 3.1 1.5 0.2 setosa
143 5.8 2.7 5.1 1.9 virginica
40 5.1 3.4 1.5 0.2 setosa
93 5.8 2.6 4.0 1.2 versicolor이제 test나 validation으로 거친 데이터들이 얼마나 잘 예측하거나 분류했는지를 측정하는 지표가 있어야 할 것이다.
Confusion Matrix
오분류표라고 불리는데, 대부분의 분류 모델에서 예측한 값과 실제 값과의 관계를 표로 만든 형태이다.
| 예측값 Prediction |
|||
| True | False | ||
| 실제값 Ground True |
True | TP | FN |
| False | FP | TN | |
각 TP, FN, FP, TN은 빈도를 나타내며, 이 값들을 토대로 지표를 만들게 된다.
- $accuracy = \frac{TP+TN}{P+N}$
- $error rate = \frac{FP+FN}{P+N}$
- $sensitivity = \frac{TP}{P}$
- $specificity = \frac{TN}{N}$
- $Precision = \frac{TP}{TP+FP}$ 좀 자주 쓰인다. P가 들어가는 것이 key point
- $Recall = \frac{TP}{TP+FN} = \frac{TP}{P}$ 좀 자주 쓰인다. Precision에서 FP가 FN으로 바뀌는 것
- $F1 = \frac{2 \times Precision \times Recall}{Precision + Recall}$ 가장 중요 걍 외우기
- $F_{\beta} = \frac{(1 + \beta^2) \times Precision \times Recall}{\beta^2 \times Precision + Recall}$
ROC Curve
y축은 Sensitivity(전체 맞다고 예측한 것중에 실제로 True), x축은 (1-specificity(아니라고 에측한 것중에 실제로 False))로 그려지는 곡선이다. 보통 threshold를 여러개 잡아서 그리게 되며, 이 곡선이 보통 다음 그래프 형태를 띈다.
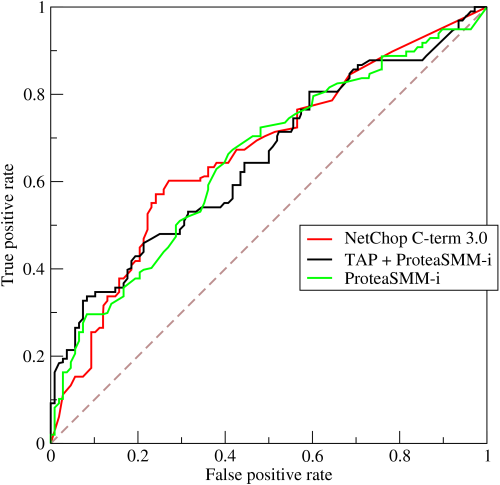
NetChop C-term이라는 모델과 TAP + ProteaSMM-i 한 앙상블 모델, ProteaSMM-i 모델이 있는 것 같다(자세힌 모름). ROC의 밑부분 면적(적분한거)를 보통 AUC라고 부르며 이 AUC가 넓으면 넓을 수록 좋은 모형으로 평가가 된다. 따라서 NetChop C-term이 거의 다른 모델보다 우수한 모델이라고 볼 수 있다.
이익(gain) 도표와 lift curve
여기서는 데이터가 대부분 예측 할 확률에 대해 정리가 됨을 미리 알고 들어가자. 그래서 데이터를 상위 몇% 하위 몇%로 자를 수 있다.
이익 도표
모델의 성능을 평가할 때 사용하는 시각화 도구이다. 보통 분류 문제에서 사용되고, 정렬된 데이터에 대해 예측 모델의 누적 이익을 시각적으로 나타낸다. 모델의 효율성과 효과를 직관적으로 파악을 할 수 있다.
- 누적이익(Cummulative Gain): 주어진 데이터를 모델의 예측 확률에 따라 정렬을 하고, 상위부터 일정 비율의 데이터를 선택했을 때, 해당 데이터에 대해 실제로 긍정 클래스로 예측된 비율을 누적으로 나타낸다.
- 이익곡선(Gain Curve): X축에 선택된 데이터의 비율, Y축에 해당 비율 내에서의 긍정 클래스의 누적 비율을 표시한다.
library(gains)
set.seed(123)
actual <- c(1, 0, 1, 0, 1, 1, 0, 0, 1, 0)
predicted <- runif(10, min=0, max=1)
gain_table <- gains(actual, predicted)
gain_table
plot(gain_table, main="Gain Chart for Marketing Campaign",
xlab="Percentage of Data", ylab="Percentage of Purchases",
cex.main=1.4, cex.lab=1.2)Depth Cume Cume Pct Mean
of Cume Mean Mean of Total Lift Cume Model
File N N Resp Resp Resp Index Lift Score
-------------------------------------------------------------------------
10 1 1 1.00 1.00 20.0% 200 200 0.94
20 1 2 0.00 0.50 20.0% 0 100 0.89
30 1 3 0.00 0.33 20.0% 0 67 0.88
40 1 4 0.00 0.25 20.0% 0 50 0.79
50 1 5 1.00 0.40 40.0% 200 80 0.55
60 1 6 0.00 0.33 40.0% 0 67 0.53
70 1 7 0.00 0.29 40.0% 0 57 0.46
80 1 8 1.00 0.38 60.0% 200 75 0.41
90 1 9 1.00 0.44 80.0% 200 89 0.29
100 1 10 1.00 0.50 100.0% 200 100 0.05
Lift Curve
이 또한 분류 문제에서 자주 사용되는 시각화 방법이다. Lift는 다음을 가르킨다.
$$Lift = \frac{TP + TN}{}$$
상위 10%의 데이터에서 긍정 클래스를 모델이 30% 예측했다면, 무작위로 선택했을 때 긍정 클래스 비율이 10% 라면 리프트는 3이 된다.
library(gains)
set.seed(123)
actual <- c(1, 0, 1, 0, 1, 1, 0, 0, 1, 0)
predicted <- runif(10, min=0, max=1)
gain_table <- gains(actual, predicted)
lift_values <- gain_table$mean.resp / mean(actual)
plot(gain_table$cume.pct.of.total, lift_values, type="l",
main="Lift Curve for Marketing Campaign",
xlab="Percentage of Data", ylab="Lift",
cex.main=1.4, cex.lab=1.2, col="blue")
abline(h=1, col="red", lty=2)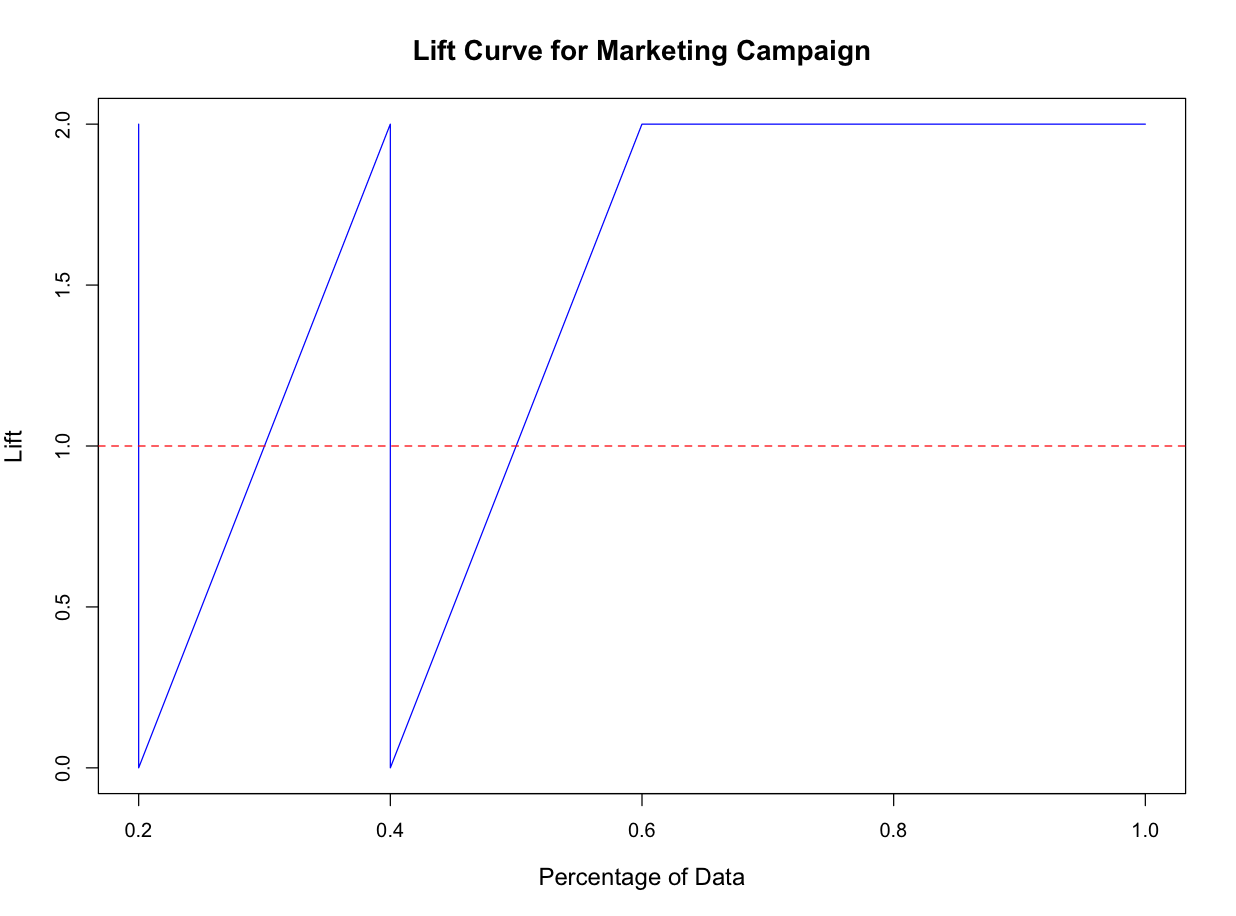
X축은 데이터를 정렬한 후에 선택한 비율을 나타내고, Y축은 선택한 비율에 대한 lift 값을 나타낸다. 보통 1보다 크면 모델이 무작위 선택보다 성능이 좋은것이며, 1이면 무작위 선택과 동일한 성능을 보이게 되는 것이다.
'AI > ADP' 카테고리의 다른 글
| [ADP] 4장 데이터 분석 - 연관 분석 (0) | 2024.08.06 |
|---|---|
| [ADP] 4장 데이터 분석 - 군집 분석 (0) | 2024.08.06 |
| [ADP] 4장 데이터 분석 - Ensemble (0) | 2024.08.03 |
| [ADP] 4장 데이터 분석 - Decision Tree (0) | 2024.08.03 |
| [ADP] 4장 데이터 분석 - 신경망 모형 (1) | 2024.08.03 |


