
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Reference Type
- Inheritance
- zsh
- Polymolphism
- Class
- selenium
- Unity
- OOP
- 자바
- Mac
- 백준
- python
- Entity Set
- X.org
- 리눅스 기초
- 리눅스 마스터 1급
- BFS
- 리눅스
- 셀레니움
- X윈도우
- dbms
- systemd
- preprocessing
- Physical Scheme
- Java
- literal
- Entity
- External Scheme
- Binary Search
- Operator
- Today
- Total
Byeol Lo
[ADP] 2장 데이터 처리 기술 이해 - 데이터 처리 프로세스, ETL 본문
ETL은 데이터 이동과 변환 절차와 관련된 업계 표준 용어임. ETL은 데이터 웨어 하우스(DW, Data Warehouse), 운영 데이터 스토어(ODS, Operational Data Store), 데이터 마트(DM, Data Mart)에 대한 데이터 적재 작업의 핵심 구성 요소임. 데이터 통합(Data Integration), 데이터 이동(Data Migration), 마스터 데이터 관리(MDM, Master Data Management) 에 폭넓게 활용됨. 먼저 관련 시스템(DW, ODS, DM) 이 무엇인지 간단하게만 보자.
DW, Data Warehouse
여러 운영 시스템과 외부 데이터 소스에서 수집된 데이터를 통합하고, 분석가능한 형태로 저장하는 중앙 저장소임. 보통 BI 를 지원하고 있어서 데이터를 기반으로 분석이 가능하다.
- 주제 지향성(Subject-Oriented): 특정 비즈니스 주제에 맞게 데이터 설계
- 통합성(Integrated): 여러 소스에서 데이터를 가져와 일관된 형식으로 통합
- 비휘발성(Non-Volatile): 데이터가 저장되면 사라지지 않고 과거 데이터를 보존함.
- 시간 가변성(Time-Variant): 데이터가 시간에 따라 변하는 정보를 포함함.
ETL 프로세스에서 추출, 변환, 적재의 과정을 통해서 이 데이터가 DW에 들어오게 됨.
ODS, Operating Data Store
기업의 운영, 비즈니스 프로세스를 지원하기 위해 단기적으로 운영 데이터를 저장하고 관리하는 DBMS 임. 위와 비슷하지만, 단기로 저장하기 때문에 주로 최신 데이터만을 유지한다. 데이터는 ERP, POS 시스템 등 다양한 운영 시스템으로 부터 데이터를 수집하게 되고, 대표적으로 RDBMS, NoSQL 데이터 베이스를 이용해서 구현된다(빠른 입출력이 필요하기 때문에 고성능이어야 함). 단기 저장이기 때문에 오래된 데이터는 DW로 가서 저장된다. 그래서 데이터가 들어오는 파이프라인에 최전방에 위치해 있다.
DM, Data Mart
특정 비즈니스 부서나 팀의 요구를 충족시키기 위해 설계된 소규모 데이터 웨어하우스이다(특정 팀을 위한 좀 더 작은 DW라고 보면 됨). 그래서 특정 주제, 기능에 대한 데이터만 저장하며, 그 예로는 판매, 마케팅, 재무 등등이 있을 수 있고, 물리적으로는 데이터 웨어하우스 내에 존재할 수도 있고 독립된 데이터베이스 서버에 존재할 수 있는데 이건 설계 마음이고 조직에 따라 다르다.
팀이 필요로 하는 데이터만을 모으기 때문에, 전체 데이터를 다 볼 필요가 없어서 빠른 쿼리와 분석이 가능하며, 데이터 접근이 분산되기 때문에 성능 저하를 방지할 수 있으며, 보안 및 통제에 대한 책임도 분리가 가능하다.
ETL, External Transformation Loading
- Extraction: 하나 이상의 데이터 원천(source, 웹서버, POS, ERP 등등)로 부터 데이터를 획득하는 단계
- Transformation: 데이터 정제/형식 변환/표준화 등의 처리가 이루어지며, 통합 또는 다수 어플리케이션에 내장된 비즈니스 프로세스를 적용시키는 단계
- Loading: 위 변형 단계 처리가 완료된 데이터를 특정 목표 시스템(ODS, DW, DM 등등) 에 적재하는 단계
또한 ETL 작업 단계에서 정책 기반(작업을 자동화하고 관리하기 위한 규칙이나 정책)의 예약을 조정할 수 있는 재사용 가능한 컴포넌트들로 대용량 데이터를 처리하기 위한 MPP(Massive Parallel Processing)를 지원할 수 있음. MPP는 대용량 데이터를 동시에 여러프로세서에서 병렬로 처리하는 것.
이런 ETL을 구현하기 위해 여러 상용 소프트웨어가 있고 그 유형이
- 일괄(Batch) ETL
- 실시간(Real Time) ETL
로 나뉜다.
ODS와 데이터 웨어하우스

ODS와 데이터 웨어하우스에 들어오는 데이터들이 어떤 형태로 나가는지 보여주는 다이어그램이다.
- Step 0 Interface: 다양한 이기종 DBMS 및 스프레드시트 등 데이터 원천(Source)로 부터 데이터를 획득하기 위해 인터페이스 메커니즘 구현, 자바의 인터페이스를 만드는 것과 비슷하다고 보면 된다. 각각의 데이터 원천은 서로 다른 형태를 취하기 때문에 해당 데이터를 맞게 처리를 해주기 위해 상호작용에 관한 구현을 해주는 것이다.
- Step 1 Staging ETL: 정해진 주기에 따라 다양한 이기종 DBMS, ERP 시스템, CRM 시스템, 스프레드시트 파일, 또는 기타 데이터 소스로 부터 원천 시스템에서 발생한 세부적인 거래나 활동에 관한 데이터를 획득한 후(이게 extraction), Staging table이라는 추출된 데이터를 저장한다. 이는 일시적으로 저장하는 중간 테이블이며, 이 테이블은 데이터 웨어하우스 또는 ODS로 데이터를 로드하기 전에 데이터를 정리하고 변환하는데 사용한다.
- Step 2 Profiling ETL: staging table에서 데이터 특성을 식별하고(정리하고), 데이터의 변수, 필드들을 분류한다고 보면 됨 이는 staging table 에서 일어나는 처리.
- Step 3 Cleansing ETL: staging table에서 다양한 규칙들을 활용해 프로파일링 된 데이터를 보정한다. 데이터 정제 작업을 수행하는 것을 의미하는데, 결측값이나 잘못된 값을 수정한다거나, 중복을 제거한다거나, 비즈니스 규칙을 적용한다거나 이다. 여기서 cleansed tables 가 됨(별로 중요한 명칭은 아닌 듯 하다).
- Step 4 Integration ETL: (이름, 값, 구조)를 써서 데이터 충돌을 해소하고, 클렌징된 데이터를 통합한다. 데이터 형식을 일관되게 해서 데이터 충돌을 막거나 (날짜 형식을 통일, 숫자 형식을 통일, 성별 형식 통일 등등, 형식이 다르면 오류 뜨니깐) 데이터 스키마에서 서로 다른 데이터 소스에서 동일한 개념을 표현하는 다른 이름이 있는 경우 통일된 이름으로 표준화를 한다거나 (어떤 데이터의 필드, 속성이 다른걸 통일), 값의 단위가 다른걸 통일 시킨다거나(값 충돌 해소)
- Step 5 Denormalizing ETL: 운영 보고서 생성, 데이터 웨어하우스 또는 데이터 마트로의 데이터 적재를 위해 데이터 비정규화를 수행한다. 비정규화는 중복 데이터를 통해 여러 테이블에 분산 저장하고 join을 제거하여 분석을 더 용이하게 한다. 보고서를 생성하는 이유는 조직의 운영, 의사결정을 내릴 때 정보를 제공하기 위함임.
ODS 구성
이제 위의 그림에서 저 작은 저장소 ODS(Operating Data Store)를 보자(옛날엔 ODC라고도 부르는거 같다).

설명했듯이 interface, staging, profiling, cleansing, integration, export(denormalizing) 층이 있고,데이터마트나 데이터 웨어하우스로의 분산 저장을 하게 된다. 이제 위의 단계들을 더 세부적으로 보자.
Interface Layer
다양한 소스로 부터 데이터를 획득하는 단계인데, RDBMS, Spread Sheet, Flat file, Web server, xml, transaction data 등등이 있을 것이다. 여기서 다음 기술이 활용된다.
- OLEDB(Object LInking and Embedding Database): 마이크로소프트에서 개발한 데이터 액세스 기술이며, Windows OS 에서 데이터베이스와의 연결을 가능하게 한다.
- ODBC(Object Data Base Connectivity): 데이터베이스와의 연결을 위해 표준화된 인터페이스를 말하며, 다양한 DBMS과 어플리케이션 사이에서 데이터 액세스를 가능하게 한다.
- FTP(File Transfer Protocol): 네트워크 상에서 파일을 전송하기 위한 표준 프로토콜이며, 클라이언트-서버 모델을 사용해서 파일을 업로드, 다운로드 할 수 있는 방식을 제공함.
여기에 더해서
- Real Time
- Near Rear Time
- OLAP(Online Analytical Processing)
와 같은 질의를 지원하기 위한 실시간 데이터 복제 인터페이스 기술들이 함께 활용된다. 모든건 데이터를 일단 통신하기 위해서 있는 것들이다.
Staging Layer
소스로 부터 추출된 트랜잭션 데이터들이 하나 이상의 스테이징 테이블들에 저장된다. 이 테이블은 정규화가 배제되며, 테이블 스키마는 데이터 원천 구조에 의존적이라서 데이터 원천과 스테이징 테이블 사이에서 매핑은 일대일 또는 일대다로 구성되어 진다.
데이터가 스테이징 테이블에 적재되는 시점에서는 적재 타임스탬프, 데이터 값에 대한 체크 섬 등 통제 정보로 메타 데이터가 추가되며, 체크 섬 정보는 신규 데이터 항목의 추가 여부에 따른 데이터 추가 적재 필요성 판단 등에 활용된다.

Profiling Layer
범위/도메인/유일성 확보 등의 규칙을 기준으로 데이터 품질을 점검한다. 검증에는 다음 절차를 따른다.
- Requirement: profiling requirement 준비
- Profiling ETL Functions: 스테이징 테이블 내 데이터에 대한 데이터 프로파일링 수행
- Load Statistics: 데이터 프로파일링 결과 통계 처리
- Create Data Quality Report: 데이터 품질 보고서 생성 및 공유

Cleansing Layer
Cleansing ETL Specification를 통해서 앞 데이터 프로파일링 단계에서 식별된 오류 데이터들을 다음 절차에 따라 수정한다.

- Requirements: data quality report, cleansing ETL specification 준비
- cleansing stored procedure 실행
- cleansing ETL functions 실행
Integration Layer
정제된 데이터들을 ODS 내의 단일 통합 테이블에 적재하며, 다음 단계들을 거치게 된다.
- Requirements: cleansed tables, data conflict ETL specification 준비
- integration stored procedure 실행
- integration ETL functions 실행
Export Layer
통합된 데이터를 export 규칙과 보안 규칙을 적용시켜서 export ETL function을 수행하여 export table을 생성한 후, 다양한 전용 DBMS 클라이언트, DM, DW 등에 적재시킨다. 여기서 OLAP란 사용자 혹은 시스템이 다차원 정보에 접근할 수 있도록 하여 대화식으로 정보를 분석하고 의사결정을 지원하는 시스템임.
Data Warehouse
ODS를 거친 데이터는 데이터 분석과 보고서 생성을 위해 데이터 웨어하우스에 적재된다. 특징으로는 다음과 같다.
- Subject Oriented: 업무 상황의 특정 이벤트나 업무 항목을 기준으로 구조화
- Non Volatile: 데이터 웨어하우스의 데이터는 최초 저장 이후에는 읽기 전용(Read Only) 속성을 가지며 삭제되지 않음
- Integrated: 대부분의 운영 시스템들에 의해 생성된 데이터들의 통합본임
- Time Variant: 보통 사원들이 보는 운영 시스템들은 최신 데이터를 보유하고 있지만, 데이터 웨어하우스는 시간순에 의한 이력 데이터를 보유함
데이터 웨어하우스의 테이블들은 스타 스키마(Star Schema) 또는 스노우 플래이크 스키마(Snow Flake Schema)로 모델링된다.
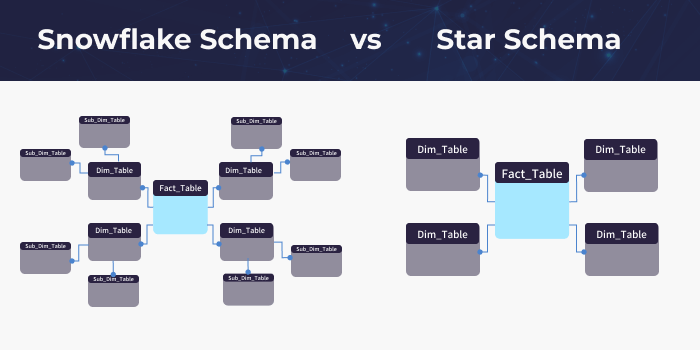
Star Schema
Join Schema 라고도 하며, 데이터 웨어하우스 스키마 중 가장 단순하다. 중앙을 단일 사실 테이블(Fact Table)이라고 하며, 중앙과 연결된 다수의 테이블들을 차원 테이블(Dimensional Table)이라고 함.
- 다차원 데이터베이스(Multi-Dimensional Database) 기능을 구현 가능
- Fact Table은 보통 제 3정규형(3NF)으로 모델링되어 있음(요새는 BCNF, 3.5NF 를 따르는게 보통)
- Dimensional Table은 보통 비정규화(de-normalized)된 제 2정규형(2NF)로 모델링 함.
- Dimensional Table을 정규화 한 것을 스노우 플레이크 스키마라고 함
- Snowflake schema에 비해 복잡도가 낮아서 이해하기 쉽고, 쿼리 작성 용이
- 조인 테이블 개수가 적음
- Dimensional Table의 비정규화에 따른 데이터 중복으로 해당 테이블의 데이터 적재 시 상대적으로 많은 시간이 소요됨
Snowflake Schema
스타스키마 보다는 복잡성이 높지만, 차원 테이블을 제 3정규형으로 정규화 함으로써 얻는 데이터 중복 처리로, 데이터 적재 시간이 단축되지만, 테이블 개수 증가와 쿼리 작성 난이도가 상승됨.

'AI > ADP' 카테고리의 다른 글
| [ADP] 2장 데이터 처리 기술 이해 - 데이터 처리 프로세스, EAI(Enterprise Application Integration) (0) | 2024.07.16 |
|---|---|
| [ADP] 2장 데이터 처리 기술 이해 - 데이터 처리 프로세스, CDC(Change Data Capture) (0) | 2024.07.16 |
| [ADP] 1장 데이터의 이해 - 데이터의 가치와 미래 (0) | 2024.07.11 |
| [ADP] 1장 데이터의 이해 - 데이터베이스 (1) | 2024.07.05 |
| [ADP] 1장 데이터의 이해 - 데이터의 이해 (0) | 2024.07.05 |

